Intersubject Correlation¶
Written by Juha Lahnakoski and Luke Chang
Synchrony between individuals happens at several levels from behavior to brain activity (Nummenmaa et al., 2018, Nastase et al., 2019). To an observer, synchrony during interaction or joint motion (Hale et al., 2020) can reflect prosocial qualities such rapport (Miles et al., 2009) or affiliation (Hove and Risen, 2009). During physically arousing ritualistic experiences, observers may selectively synchronize their heart rates while observing related, but not unrelated individuals participating in the ritual (Konvalinka et al., 2011) and the degree of affective synchrony can predict the perceived social connection between two individuals (Cheong et al., 2020). Synchrony of brain activity is associated with, among other things, shared psychological perspectives toward a stimulus (Lahnakoski et al., 2014, Yeshurun et al., 2017, Yeshurun et al., 2017, Kang & Wheatley, 2017, Cheong et al., 2020) and friendship (Parkinson et al., 2018), and may also be disturbed in psychiatric conditions ranging from developmental conditions such as autism (Hasson et al., 2009; Salmi et al., 2013, Byrge et al., 2015) to more acute conditions such as first-episode psychosis (Mäntylä et al., 2018). Thus, measures of synchrony can offer a simple window to many psychological processes.
In brain imaging, synchrony of brain activity is most commonly measured using intersubject correlations (ISC; Hasson et al., 2004). As the name implies, this method calculates linear correlations between participants and derives summary statistics from these correlations to measure the level of similarity of brain activity. Overall, the brain activity measured with fMRI during naturalistic stimulation conditions can be thought to consist of four main sources: (1) stimulus-driven brain activity between individuals shared by all or most of the participants, (2) individual or idiosyncratic activity elicited by the stimulus, (3) intrinsic activity that is not time-locked to the stimulus, and (4) noise from various sources. The idea behind ISC is to identify brain activity that is shared by a large proportion of the participants (category 1). Thus, this method evaluates how much of an individual’s brain activity is explained by this shared component. By contrast, if smaller groups of participants, e.g. pairs of friends within the study, share similar individual activity patterns (category 2), it may be better captured by the dyadic values in the pairwise matrices using techniques such as IS-RSA (Parkinson et al., 2018, Chen et al., 2020, Finn et al., 2020). Generally, the third category of activity is not readily detected by synchrony approaches (Chang et al., 2018). However, with inventive experimental designs, e.g. during verbal recall of previously experienced stimuli (Chen et al., 2017), it is still possible to extract shared brain activity patterns by temporally reorganizing the data, even when the original experiences of the participants were out of sync. The optimal choice of analysis will depend on the research question and the type of shared activity patterns that are of particular interest. Most commonly, ISCs are calculated locally within each voxel (or region), but this approach has also been extended to functional connectivity (Simony et al., 2016). Intersubject correlations give a summary statistic of synchrony over long periods of time, usually over an entire imaging session. However, the level of synchrony may change considerably from one moment to the next with the experimental condition and can be investigated using time-varying measures of synchrony.
In this tutorial, we will cover:
how to compute pairwise ISC
how to perform hypothesis tests with ISC
how to perform ISFC (also see the Dynamic Connectivity tutorial)
how to perform dynamic ISC
Let’s get started by watching some short videos illustrating how ISC can be used with naturalistic data.
Dr. Yaara Yeshurun, PhD, an Assistant Professor at Tel-Aviv University, will provide two example applications of how ISC can be used to characterize the brain mechanisms underlying shared understanding.
from IPython.display import YouTubeVideo
YouTubeVideo('pvYNjG1jvQE')
YouTubeVideo('wEKKTG7Q1DQ')
Computing Intersubject Correlation¶
Pairwise vs Average Response¶
Generally, ISCs are calculated using one of two main approaches. First, one calculates pairwise correlations between all participant pairs to build a full intersubject correlation matrix. The second approach, uses the average activity timecourse of the other participants as a model for each individual left out participant. This procedure produces individual, rather than pairwise, spatial maps of similarity reflecting how similarly, or “typically”, each person’s brain activates. These maps lend themselves to similar analyses as one might perform with first level results of a traditional general linear model (GLM) analysis. However, some of the individual variability is lost with the latter approach, and thus the ISC values are typically of much higher magnitude compared to the pairwise matrices.
Summary Statistic¶
The next step after computing either the pairwise or average similarity across participants is to summarize the overall level of synchrony across participants. A straightforward approach is to compute the mean correlation. However, to make the correlation coefficients more normally distributed across the range of values, the Fisher’s Z transformation (inverse hyperbolic tangent) is typically applied before computing the mean correlation. The Fisher’s Z transformation mainly affects the higher end of absolute correlation values, eventually stretching the correlation coefficient 1 to infinity. However, with the typical range of values of pairwise ISCs, the effects of this transformation are relatively small reaching ~10% at the higher end of the scale of r=0.5. More recently, it has been suggested that computing the median, particularly when using the pairwise approach, provides a more accurate summary of the correlation values (Chen et al., 2016).
Hypothesis tests¶
Performing hypothesis tests that appropriately account for the false positive rate can be tricky with ISC because of the dependence between the pairwise correlation values and the inflated number of variables in the pairwise correlation matrices. Though there have been proposals to use mixed-effects models for a parametric solution (Chen et al., 2017), we generally recommend using non-parametric statistics when evaluating the significance of these correlations.
There are two general non-parametric approaches to performing hypothesis tests with ISC. The first method is a permutation or randomization method, achieved by creating surrogate data and repeating the same analysis many times to build an empirical null distribution (e.g. 5-10k iterations). However, to meet the exchangeability assumption, it is important to consider the temporal dependence structure. Surrogate data can be created by circularly shifting the timecourses of the participants, or scrambling the phases of the Fourier transform of the signals and transforming these scrambled signals back to the time domain (Theiler et al., 1992, Lancaster et al., 2018). Various blockwise scrambling techniques have also been applied and autoregressive models have been proposed to create artificial data for statistical inference . These approaches have the benefit that, when properly designed, they retain important characteristics of the original signal, such as the frequency content and autocorrelation, while removing temporal synchrony in the data.
To illustrate these permutation based approaches, the animation below depicts the process of creating these null distributions and compares these to a similar distribution built based on real resting state data of the same duration in the same participants recorded just prior to the movie data in the same imaging study. Resting state is an ideal condition for demonstrating the true null distribution of no synchrony intersubject correlation as it involves no external synchronizing factors apart from the repeating noise of the scanner gradients, which are generally not of interest to us. Thus, any correlations in the resting state data arise by chance. As can be seen, the null distributions based on the surrogate data follow the distribution of resting state ISCs well as the number of iterations increases. However, the distributions are sometimes considered too liberal.
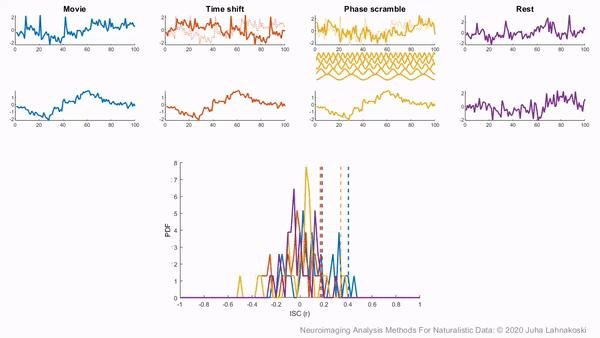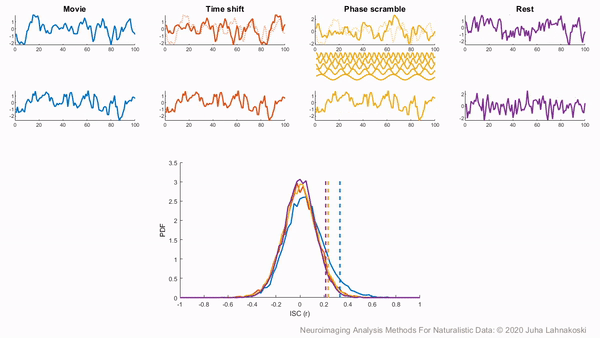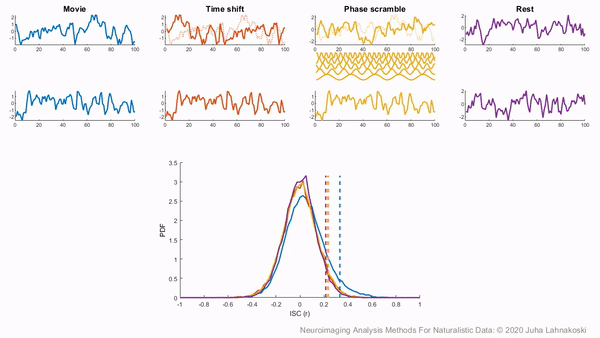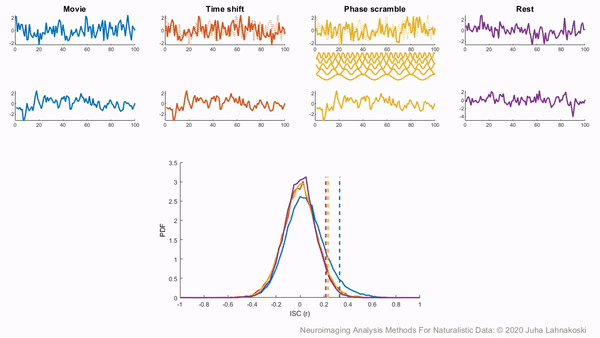
The second approach employs a subject-wise bootstrap on the pairwise similarity matrices. Essentially, participants are randomly sampled with replacement and then a new similarity matrix is computed with these resampled participants. As a consequence of the resampling procedure, sometimes the same subjects are sampled multiple times, which introduces correlation values of 1 off the diagonal. Summarizing the ISC using the median can minimize the impact of these outliers. These values are then shifted by the real summary statistics to produce an approximately zero-centered distribution. Python implementations in Brainiak and nltools convert these values to NaNs by default so that they are not included in the overall ISC summary statistic. If you would like to learn more about resampling methods, we encourage you to read our brief introduction available on the dartbrains course.
Getting Started¶
Before getting started with this tutorial, we need to make sure you have the necessary software installed and data downloaded.
Software¶
This tutorial requires the following Python packages to be installed. See the Software Installation tutorial for more information.
seaborn
matplotlib
numpy
scipy
pandas
nltools
nilearn
sklearn
networkx
datalad
Let’s now load the modules we will be using for this tutorial.
%matplotlib inline
import os
import glob
import numpy as np
from numpy.fft import fft, ifft, fftfreq
import pandas as pd
import matplotlib.pyplot as plt
from matplotlib import gridspec
from matplotlib.animation import FuncAnimation
import seaborn as sns
from nltools.data import Brain_Data, Adjacency
from nltools.mask import expand_mask, roi_to_brain
from nltools.stats import isc, isfc, isps, fdr, threshold, phase_randomize, circle_shift, _butter_bandpass_filter, _phase_mean_angle, _phase_vector_length
from nilearn.plotting import view_img_on_surf, view_img
from sklearn.metrics import pairwise_distances
from sklearn.utils import check_random_state
from scipy.stats import ttest_1samp
from scipy.signal import hilbert
import networkx as nx
from IPython.display import HTML
# import nest_asyncio
# nest_asyncio.apply()
import datalad.api as dl
/Users/lukechang/anaconda3/lib/python3.7/site-packages/matplotlib/image.py:13: RuntimeWarning: coroutine 'run_async_cmd' was never awaited
import PIL.PngImagePlugin
RuntimeWarning: Enable tracemalloc to get the object allocation traceback
Data¶
This tutorial will be using the Sherlock dataset and will require downloading the Average ROI csv files.
We have already extracted the data for you to make this easier and have written out the average activity within each ROI into a separate csv file for each participant. If you would like to get practice doing this yourself, here is the code we used. Note that we are working with the hdf5 files as they load much faster than the nifti images, but either one will work for this example.
for scan in ['Part1', 'Part2']:
file_list = glob.glob(os.path.join(data_dir, 'fmriprep', '*', 'func', f'*crop*{scan}*hdf5'))
for f in file_list:
sub = os.path.basename(f).split('_')[0]
print(sub)
data = Brain_Data(f)
roi = data.extract_roi(mask)
pd.DataFrame(roi.T).to_csv(os.path.join(os.path.dirname(f), f"{sub}_{scan}_Average_ROI_n50.csv" ), index=False)
You will want to change data_dir to wherever you have installed the Sherlock datalad repository. We will initialize a datalad dataset instance and get the files we need for this tutorial. If you’ve already downloaded everything, you can skip this cell. See the Download Data Tutorial for more information about how to install and use datalad.
data_dir = '/Volumes/Engram/Data/Sherlock'
# If dataset hasn't been installed, clone from GIN repository
if not os.path.exists(data_dir):
dl.clone(source='https://gin.g-node.org/ljchang/Sherlock', path=data_dir)
# Initialize dataset
ds = dl.Dataset(data_dir)
# Get Cropped & Denoised CSV Files
result = ds.get(glob.glob(os.path.join(data_dir, 'fmriprep', '*', 'func', f'*Average_ROI*csv')))
ISC Analysis Tutorial¶
Ok, now let’s see how ISC works with real data. In this tutorial, we will be computing ISC on average activity within 50 ROIs using data from the Sherlock dataset using the nltools Python toolbox. We also recommend checking out the Brainiak tutorial, and the Matlab ISC-Toolbox (Kauppi et al., 2014).
Ok, now let’s download the k=50 whole brain meta-analytic parcellation of the neurosynth database (de la Vega, 2016) from neurovault. Each ROI is indicated with a unique integer. We can expand this mask into 50 separate binary masks with the expand_mask function.
mask = Brain_Data('http://neurovault.org/media/images/2099/Neurosynth%20Parcellation_0.nii.gz')
mask_x = expand_mask(mask)
mask.plot()

Now, let’s load the csv files for each participant. Remember, Sherlock viewing was separated into two 25 minute runs. We will need to combine these separately for each participant. There are many different ways to do this step. In this example, we will be storing everything in a dictionary.
sub_list = [os.path.basename(x).split('_')[0] for x in glob.glob(os.path.join(data_dir, 'fmriprep', '*', 'func', '*Part1*csv'))]
sub_list.sort()
sub_timeseries = {}
for sub in sub_list:
part1 = pd.read_csv(os.path.join(data_dir, 'fmriprep', sub, 'func', f'{sub}_Part1_Average_ROI_n50.csv'))
part2 = pd.read_csv(os.path.join(data_dir, 'fmriprep', sub, 'func', f'{sub}_Part2_Average_ROI_n50.csv'))
sub_data = part1.append(part2)
sub_data.reset_index(inplace=True, drop=True)
sub_timeseries[sub] = sub_data
Now, let’s pick a single ROI to demonstrate how to perform ISC analyses. We can pick any region, but let’s start with the vmPFC (roi=32), feel free to play with different regions as you work with the code.
We can plot the mask and create a new pandas DataFrame that has the average vmPFC activity for each participant.
roi = 32
mask_x[roi].plot()
def get_subject_roi(data, roi):
sub_rois = {}
for sub in data:
sub_rois[sub] = data[sub].iloc[:, roi]
return pd.DataFrame(sub_rois)
sub_rois = get_subject_roi(sub_timeseries, roi)
sub_rois.head()
| sub-01 | sub-02 | sub-03 | sub-04 | sub-05 | sub-06 | sub-07 | sub-08 | sub-09 | sub-10 | sub-11 | sub-12 | sub-13 | sub-14 | sub-15 | sub-16 | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 0 | 3.362605 | -1.967253 | -0.243505 | 2.527032 | 5.166227 | -0.678549 | 2.199253 | -1.646883e+00 | 0.421235 | 0.500547 | 0.361623 | 4.639737e+00 | 1.490442 | 1.806639 | 1.039467 | 3.483579e-13 |
| 1 | 0.995695 | 1.730923 | 1.552836 | 1.068784 | 4.066954 | 0.117737 | 3.184899 | 8.464993e-01 | -0.118011 | 0.981400 | -0.069505 | 2.522244e+00 | 1.145760 | -0.582861 | -0.420722 | -1.237187e-13 |
| 2 | 2.084567 | -1.940155 | 1.914897 | 1.103097 | 2.168681 | 0.030628 | 2.036096 | 1.782011e-01 | 0.984125 | 3.957482 | -0.792416 | 1.326291e+00 | 0.472309 | -3.066318 | 0.869296 | -1.931528e-02 |
| 3 | -0.217049 | -0.636084 | 1.501459 | -0.701397 | 1.704406 | 0.042397 | 2.353035 | 1.088203e+00 | 1.650786 | 3.687806 | 3.839885 | 2.105321e-02 | -2.885314 | -1.212683 | 1.213115 | -1.460159e+00 |
| 4 | -2.628723 | 1.650023 | -1.196258 | 0.079026 | 1.297944 | -0.743593 | 1.188282 | 3.375227e-13 | 1.515944 | -0.709527 | 4.874887 | 2.279356e-13 | -5.277045 | 0.232831 | 1.914874 | 1.745742e+00 |

Circle Shift Randomization¶
To perform ISC we will be using the nltools.stats.isc function. There are three different methods implemented to perform hypothesis tests (i.e., circular shifting data, phase randomization, and subject-wise bootstrap). We will walk through an example of how to run each one.
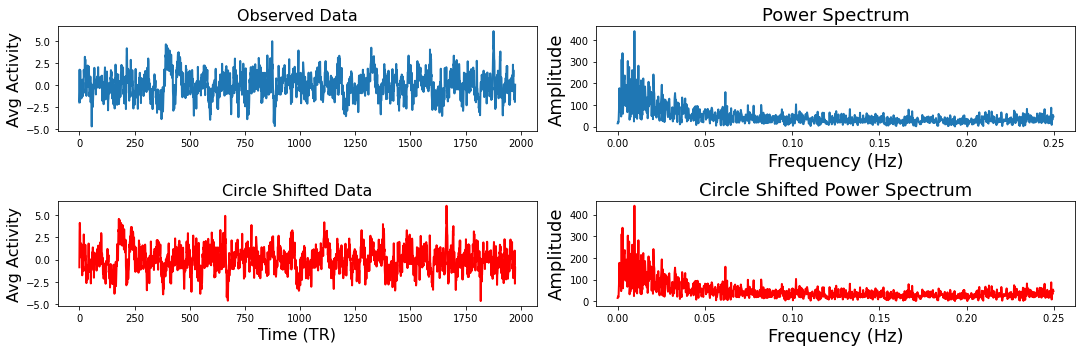
The idea behind circular shifting the data is to generate random surrogate data that has the same autoregressive and temporal properties of the original data (Lancaster et al., 2018). This is fairly straightforward and involves randomly selecting a time point to become the new beginning of the timeseries and then concatenating the rest of the data at the end so that it has the same length as the original data. Of course, there will potentially be a sudden change in the data where the two parts were merged.
To demonstrate how this works and that the circular shifted data has the same spectral properties of the original data, we will plot one subject’s time series and shift it using the nltools.stats.circle_shift function. Next to both timeseries we plot the coefficients from a fast fourier transform.
sub = 'sub-02'
sampling_freq = .5
f,a = plt.subplots(nrows=2, ncols=2, figsize=(15, 5))
a[0,0].plot(sub_rois[sub], linewidth=2)
a[0,0].set_ylabel('Avg Activity', fontsize=16)
a[0,1].set_xlabel('Time (TR)', fontsize=18)
a[0,0].set_title('Observed Data', fontsize=16)
fft_data = fft(sub_rois[sub])
freq = fftfreq(len(fft_data), 1/sampling_freq)
n_freq = int(np.floor(len(fft_data)/2))
a[0,1].plot(freq[:n_freq], np.abs(fft_data)[:n_freq], linewidth=2)
a[0,1].set_xlabel('Frequency (Hz)', fontsize=18)
a[0,1].set_ylabel('Amplitude', fontsize=18)
a[0,1].set_title('Power Spectrum', fontsize=18)
circle_shift_data = circle_shift(sub_rois[sub])
a[1,0].plot(circle_shift_data, linewidth=2, color='red')
a[1,0].set_ylabel('Avg Activity', fontsize=16)
a[1,0].set_xlabel('Time (TR)', fontsize=16)
a[1,0].set_title('Circle Shifted Data', fontsize=16)
fft_circle = fft(circle_shift_data)
a[1,1].plot(freq[:n_freq], np.abs(fft_circle)[:n_freq], linewidth=2, color='red')
a[1,1].set_xlabel('Frequency (Hz)', fontsize=18)
a[1,1].set_ylabel('Amplitude', fontsize=18)
a[1,1].set_title('Circle Shifted Power Spectrum', fontsize=18)
plt.tight_layout()
Now that you understand how the circular shifting method works with a single time series, let’s compute the ISC of the Sherlock viewing data within the vmPFC roi with 5000 permutations. The function outputs a dictionary that contains the ISC values, the p-value, the 95% confidence intervals, and optionally returns the 5000 samples. All of the permutation and bootstraps are parallelized and will use as many cores as your computer has available.
stats_circle = isc(sub_rois, method='circle_shift', n_bootstraps=5000, return_bootstraps=True)
print(f"ISC: {stats_circle['isc']:.02}, p = {stats_circle['p']:.03}")
ISC: 0.074, p = 0.0002
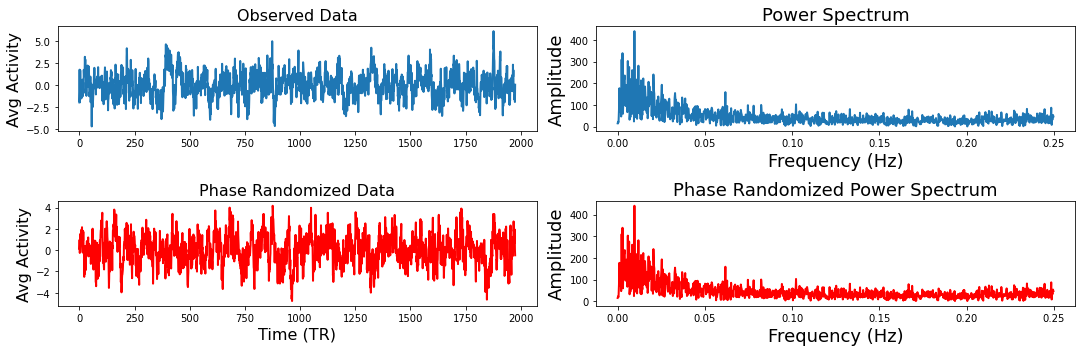
Phase Randomization¶
Next we will show how phase randomization works. This method projects the data into frequency space using a fast fourier transform and randomizes the phase and then projects the data back into the time domain (Theiler et al., 1992, Lancaster et al., 2018). Similar to the circular shifting method, this generates a random surrogate of the data, while maintaining a similar temporal and autoregressive structure as the original data. We will generate the same plots from the example above to illustrate how this works using the nltools.stats.phase_randomize function.
sub = 'sub-02'
sampling_freq = .5
f,a = plt.subplots(nrows=2, ncols=2, figsize=(15, 5))
a[0,0].plot(sub_rois[sub], linewidth=2)
a[0,0].set_ylabel('Avg Activity', fontsize=16)
a[0,1].set_xlabel('Time (TR)', fontsize=18)
a[0,0].set_title('Observed Data', fontsize=16)
fft_data = fft(sub_rois[sub])
freq = fftfreq(len(fft_data), 1/sampling_freq)
n_freq = int(np.floor(len(fft_data)/2))
a[0,1].plot(freq[:n_freq], np.abs(fft_data)[:n_freq], linewidth=2)
a[0,1].set_xlabel('Frequency (Hz)', fontsize=18)
a[0,1].set_ylabel('Amplitude', fontsize=18)
a[0,1].set_title('Power Spectrum', fontsize=18)
phase_random_data = phase_randomize(sub_rois[sub])
a[1,0].plot(phase_random_data, linewidth=2, color='red')
a[1,0].set_ylabel('Avg Activity', fontsize=16)
a[1,0].set_xlabel('Time (TR)', fontsize=16)
a[1,0].set_title('Phase Randomized Data', fontsize=16)
fft_phase = fft(phase_random_data)
a[1,1].plot(freq[:n_freq], np.abs(fft_phase)[:n_freq], linewidth=2, color='red')
a[1,1].set_xlabel('Frequency (Hz)', fontsize=18)
a[1,1].set_ylabel('Amplitude', fontsize=18)
a[1,1].set_title('Phase Randomized Power Spectrum', fontsize=18)
plt.tight_layout()
stats_phase = isc(sub_rois, method='phase_randomize', n_bootstraps=5000, return_bootstraps=True)
print(f"ISC: {stats_phase['isc']:.02}, p = {stats_phase['p']:.03}")
ISC: 0.074, p = 0.0002
As you can see the ISC value is identical as the median of the pairwise correlations are identical. The p-values are also similar and likely reflect the limited precision of the possible p-values that can be computed using only 5,000 permutations. For greater precision, you will need to increase the number of permutations, but remember that this will also increase the computational time.
Subject-wise Bootstrapping¶
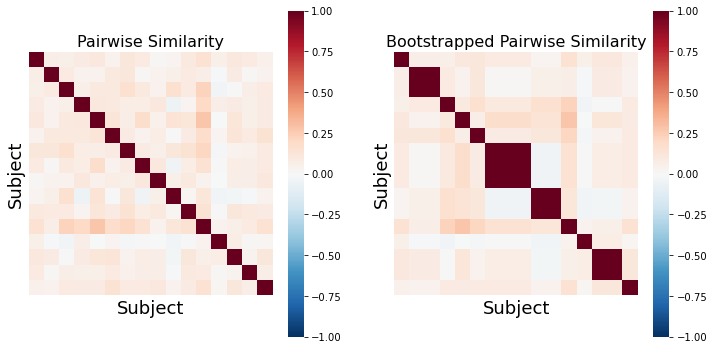
The final approach we will illustrate is subject-wise bootstrapping of the pairwise similarity matrix. This approach is more conservative than the previously described methods and is almost an order of magnitude faster shuffling the similarity matrix rather than recomputing the pairwise similarity for the null distribution (Chen et al., 2016). Bootstrapping and permutation tests are different types of resampling statistics (see our resampling tutorial for a more in depth overview). Bootstrapping is typically used more for generating confidence intervals around an estimator, while permutation tests are used for performing hypothesis tests. However, p-values can also be computed using a bootstrap by subtracting the ISC from the null distribution and evaluating the percent of samples from the distribution that are smaller than the observed ISC (Hall et al., 1991).
Just like the examples above, we will illustrate what an example bootstrapped similarity matrix looks like. Notice how some subjects are repeatedly resampled, which means that there are multiple values of perfect correlations found off the diagonal. This should be accounted for by using the median summary statistic of the lower triangle. However, both Brainiak and nltools toolboxes convert these values to NaNs to minimize the impact of these outliers on the summary statistic.
def bootstrap_subject_matrix(similarity_matrix, random_state=None):
'''This function shuffles subjects within a similarity matrix based on recommendation by Chen et al., 2016'''
random_state = check_random_state(random_state)
n_sub = similarity_matrix.shape[0]
bootstrap_subject = sorted(random_state.choice(np.arange(n_sub), size=n_sub, replace=True))
return similarity_matrix[bootstrap_subject, :][:, bootstrap_subject]
similarity = 1 - pairwise_distances(pd.DataFrame(sub_rois).T, metric='correlation')
f,a = plt.subplots(ncols=2, figsize=(12, 6), sharey=True)
sns.heatmap(similarity, square=True, cmap='RdBu_r', vmin=-1, vmax=1, xticklabels=False, yticklabels=False, ax=a[0])
a[0].set_ylabel('Subject', fontsize=18)
a[0].set_xlabel('Subject', fontsize=18)
a[0].set_title('Pairwise Similarity', fontsize=16)
sns.heatmap(bootstrap_subject_matrix(similarity), square=True, cmap='RdBu_r', vmin=-1, vmax=1, xticklabels=False, yticklabels=False, ax=a[1])
a[1].set_ylabel('Subject', fontsize=18)
a[1].set_xlabel('Subject', fontsize=18)
a[1].set_title('Bootstrapped Pairwise Similarity', fontsize=16)
Text(0.5, 1.0, 'Bootstrapped Pairwise Similarity')
stats_boot = isc(sub_rois, method='bootstrap', n_bootstraps=5000, return_bootstraps=True)
print(f"ISC: {stats_boot['isc']:.02}, p = {stats_boot['p']:.03}")
ISC: 0.074, p = 0.0002
The bootstrap procedure tends to run much faster than the permutation methods on our computer, which is one of the reasons that the authors of the toolbox recommend this approach, beyond it being more conservative (Chen et al., 2016).
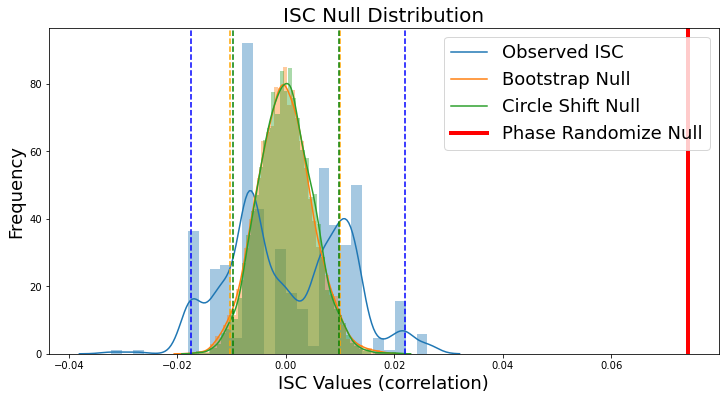
Null Distributions¶
Since each of our examples saved the null distribution, we can plot a histogram of the null distribution from each method including the confidence intervals. Notice that the circle shift and phase randomization methods produce highly similar null distributions and confidence intervals, while the bootstrap method has a wider and less symmetric distribution with the current number of iterations. However, the observed ISC of 0.074 (red line) exceeds all of the samples from the null distribution yielding a very small p-value. Notice that our observed null distributions using the surrogate data derived from the Sherlock data are very similar to the animation of null data presented above.
plt.figure(figsize=(12,6))
sns.distplot(stats_boot['null_distribution'] - stats_boot['isc'], kde=True, label='Bootstrap')
sns.distplot(stats_circle['null_distribution'], kde=True, label='Bootstrap')
sns.distplot(stats_phase['null_distribution'], kde=True, label='Bootstrap')
plt.ylabel('Frequency', fontsize=18)
plt.xlabel('ISC Values (correlation)', fontsize=18)
plt.title('ISC Null Distribution', fontsize=20)
plt.axvline(stats_boot['isc'], linestyle='-', color='red', linewidth=4)
plt.legend(['Observed ISC', 'Bootstrap Null','Circle Shift Null', 'Phase Randomize Null'], fontsize=18)
plt.axvline(stats_boot['ci'][0] - stats_boot['isc'], linestyle='--', color='blue')
plt.axvline(stats_boot['ci'][1] - stats_boot['isc'], linestyle='--', color='blue')
plt.axvline(stats_circle['ci'][0], linestyle='--', color='orange')
plt.axvline(stats_circle['ci'][1], linestyle='--', color='orange')
plt.axvline(stats_phase['ci'][0], linestyle='--', color='green')
plt.axvline(stats_phase['ci'][1], linestyle='--', color='green')
/Users/lukechang/anaconda3/lib/python3.7/site-packages/seaborn/distributions.py:2557: FutureWarning: `distplot` is a deprecated function and will be removed in a future version. Please adapt your code to use either `displot` (a figure-level function with similar flexibility) or `histplot` (an axes-level function for histograms).
warnings.warn(msg, FutureWarning)
/Users/lukechang/anaconda3/lib/python3.7/site-packages/seaborn/distributions.py:2557: FutureWarning: `distplot` is a deprecated function and will be removed in a future version. Please adapt your code to use either `displot` (a figure-level function with similar flexibility) or `histplot` (an axes-level function for histograms).
warnings.warn(msg, FutureWarning)
/Users/lukechang/anaconda3/lib/python3.7/site-packages/seaborn/distributions.py:2557: FutureWarning: `distplot` is a deprecated function and will be removed in a future version. Please adapt your code to use either `displot` (a figure-level function with similar flexibility) or `histplot` (an axes-level function for histograms).
warnings.warn(msg, FutureWarning)
<matplotlib.lines.Line2D at 0x7f8b50b81ad0>
Whole brain ISC¶
Now, let’s calculate ISC looping over each of the 50 ROIs from the whole-brain meta-analytic parcellation (de la Vega, 2016). Here we loop over each ROI and grab the column from each subject’s dataframe. We then run ISC on the combined subject’s ROI timeseries using the median method and compute a hypothesis test using the subject-wise bootstrap method with 5000 samples (Chen et al., 2016). Finally, we convert each correlation and p-value from each region back into a Brain_Data instance.
isc_r, isc_p = {}, {}
for roi in range(50):
stats = isc(get_subject_roi(sub_timeseries, roi), n_bootstraps=5000, metric='median', method='bootstrap')
isc_r[roi], isc_p[roi] = stats['isc'], stats['p']
isc_r_brain, isc_p_brain = roi_to_brain(pd.Series(isc_r), mask_x), roi_to_brain(pd.Series(isc_p), mask_x)
Now we can plot the ISC values to visualize which regions had a higher overall ISC.
isc_r_brain.plot(cmap='RdBu_r')

view_img(isc_r_brain.to_nifti())
We can threshold using bonferroni correction (p < 0.001 for k=50 parcellation). Alternatively, we can threshold using false discovery rate, by setting thr=fdr(isc_p_brain.data). In this example, FDR is more conservative than bonferroni.
view_img_on_surf(threshold(isc_r_brain, isc_p_brain, thr=.001).to_nifti())
Intersubject functional connectivity¶
Functional connectivity reflects the similarity of activity timecourses between pairs of regions and it has been particularly effective in characterizing the functional architecture of the brain during resting state, in the absence of task or external stimulation. Given enough data, these resting state correlations are stable within an individual and perturbations to the correlations between regions caused by external stimuli or tasks are relatively small (Gratton et al., 2018). Moreover, functional connectivity signals may be more effective at identifying unique functional connectivity patterns compared to resting state scans (Vanderwal et al., 2017).
To specifically address how brain regions coactivate due to naturalistic stimulation, ISC was recently extended to intersubject functional connectivity (ISFC) to measure brain connectivity between subjects (Simony et al., 2016). This method has the benefit of identifying connections that are activated consistently between participants by the stimulus while disregarding the intrinsic fluctuations as they are not time-locked between individuals. ISFC can illustrate how distant brain regions cooperate to make sense of the incoming stimulus streams. However, it can also highlight pairs of regions that show similar temporal activity patterns that are driven by the external stimulus rather than neural connections between the regions, which should be taken into account in the interpretation.
Compute average functional connectivity¶
In this tutorial, we will demonstrate how to perform ISFC using the averaging method. We iterate over each subject and compute the cross-correlation between each of the target subject’s ROIs with the average ROI response of the other subjects. This yields a separate ROI by ROI ISFC matrix for each subject. We use the nltools.stats.isfc function, but we encourage the interested reader to check out the Brainiak implementation for a faster and more feature rich option.
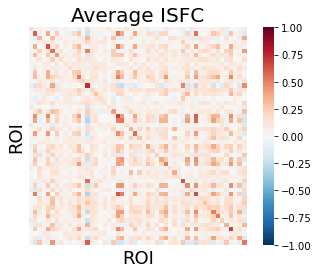
We plot the average of these matrices as a heatmap. The diagonal reflects the ROI’s ISC using the averaging method. You might recall that we used the pairwise method in the previous example to compute ISC for each ROI. Off diagonal values reflect the average intersubject functional connectivity (ISFC) between each ROI.
data = list(sub_timeseries.values())
isfc_output = isfc(data)
sns.heatmap(np.array(isfc_output).mean(axis=0), vmin=-1, vmax=1, square=True, cmap='RdBu_r', xticklabels=False, yticklabels=False)
plt.title('Average ISFC', fontsize=20)
plt.xlabel('ROI', fontsize=18)
plt.ylabel('ROI', fontsize=18)
Text(100.40000000000006, 0.5, 'ROI')
We can threshold the ISFC connectivity matrix by running a one-sample ttest on each ISFC value and correcting for multiple comparisons using FDR.
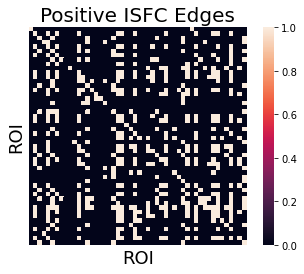
We can also convert this into an adjacency matrix, by binarizing the continuous t-values. In this example, we specifically are interested in exploring which regions have a positive ISFC. We use an arbitrary fdr threshold (q < 0.000001) in this example to create a sparse adjacency matrix.
t, p = ttest_1samp(np.array([x.reshape(-1) for x in isfc_output]), 0)
thresh = fdr(p, .0000001)
thresholded_t_pos = t.copy()
thresholded_t_pos[p > thresh] = 0
thresholded_t_pos[thresholded_t_pos <= 0] = 0
thresholded_t_pos[thresholded_t_pos > 0] = 1
thresholded_t_pos = np.reshape(thresholded_t_pos, isfc_output[0].shape)
sns.heatmap(thresholded_t_pos, square=True, xticklabels=False, yticklabels=False)
plt.title('Positive ISFC Edges', fontsize=20)
plt.xlabel('ROI', fontsize=18)
plt.ylabel('ROI', fontsize=18)
Text(100.40000000000006, 0.5, 'ROI')
We can now convert this adjacency matrix into a graph and can visualize which regions are functionally connected to the most other regions.
def plot_network(data):
'''Plot the degree of the thresholded isfc Adjaceny matrix'''
if not isinstance(data, Adjacency):
raise ValueError('data must be an Adjacency instance.')
plt.figure(figsize=(20,15))
G = data.to_graph()
pos = nx.kamada_kawai_layout(G)
node_and_degree = G.degree()
nx.draw_networkx_edges(G, pos, width=3, alpha=.4)
nx.draw_networkx_labels(G, pos, font_size=14, font_color='darkslategray')
nx.draw_networkx_nodes(G, pos, nodelist=list(dict(node_and_degree).keys()),
node_size=[x[1]*100 for x in node_and_degree],
node_color=list(dict(node_and_degree).values()),
cmap=plt.cm.Reds_r, linewidths=2, edgecolors='darkslategray', alpha=1)
plot_network(Adjacency(thresholded_t_pos, matrix_type='similarity'))
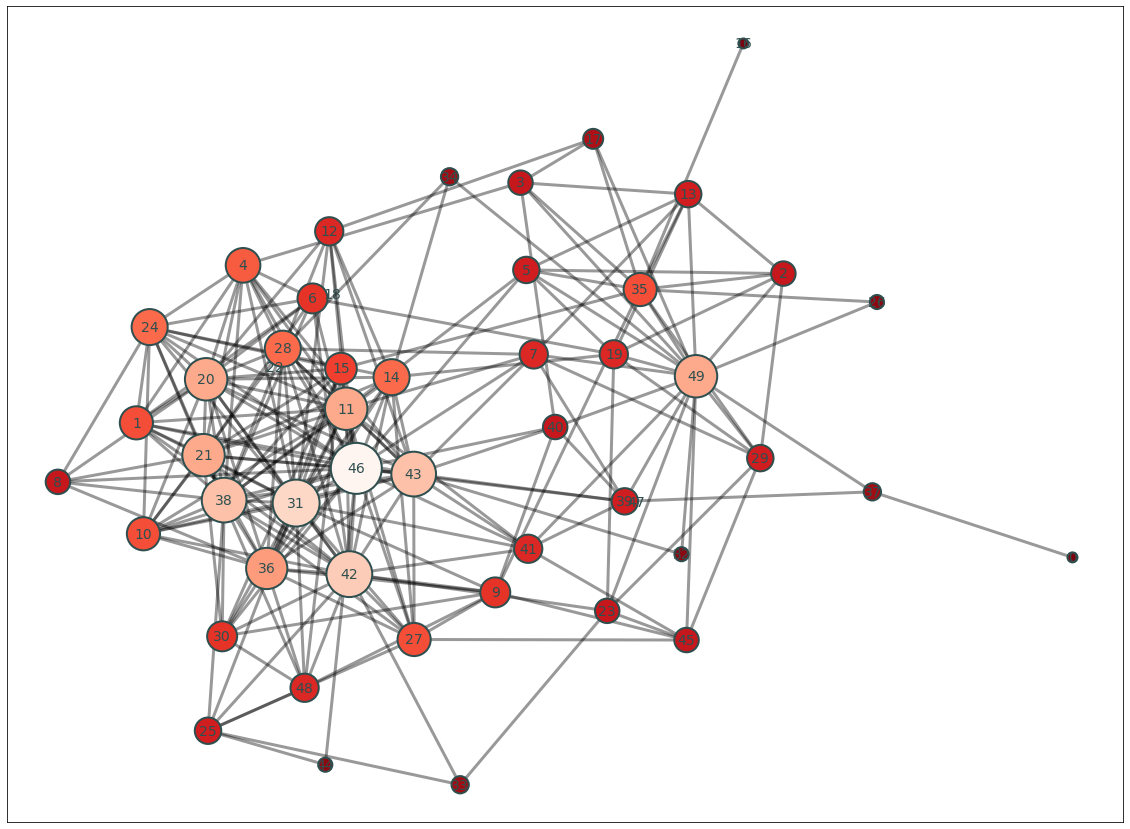
Each ROI number is not particularly informative. Most of the time, we find it helpful to project the number of connections (i.e., degree) with each node back into brain space.
degree = pd.Series(dict(Adjacency(thresholded_t_pos, matrix_type='similarity').to_graph().degree()))
brain_degree = roi_to_brain(degree, mask_x)
brain_degree.plot()
view_img_on_surf(brain_degree.to_nifti())
Temporal dynamics of intersubject synchrony¶
The majority of research has focused on correlations calculated over entire datasets to reveal the average connectivity or intersubject similarity in a group of participants. However, functional brain networks are widely thought to be dynamic. Thus, it is not clear whether tools like correlation, which assumes a constant statistical dependence between the variables over the entire imaging session, are the most appropriate way to analyze data gathered during complex naturalistic stimulation.
A simple, and popular way of looking at temporal variability of synchrony while limiting the effects of signal amplitudes is to calculate correlations within sliding time windows. This allows the estimation of synchrony also during time windows when the signals are close to their mean values as the amplitude within each time window is standardized when the correlation is calculated. However, the length of the temporal window forces a trade-off between temporal accuracy and stability of the correlation coefficient calculated in that window. Very short time windows allow one to follow precisely when correlations occur, but short windows yield extremely unstable correlations, which can be dominated completely by e.g. single co-occurring spikes or slopes. Thus, sliding-window correlations in short time-windows are often characterized by extreme correlation values that change signs wildly.
Calculating the phase synchronization or phase locking of signals is one option to estimate time-varying synchronization of signals in a way that largely separates synchronization from signal amplitudes. It has been used widely for electrophysiological measures such as EEG and MEG, and more recently also for fMRI (Glerean et al., 2012). Phase synchronization leverages the Hilbert transform to transform the real-valued signals into a complex valued, analytic signal, which is a generalization of the phasor notation of sinusoidal signals that are used widely in engineering applications.
For illustration, two examples of analytic signals with constant frequency and amplitude are shown in the bottom panel of the animation, plotted in three dimensions (real, imaginary and time axes). We have used the cosine of the angular difference as a measure of pairwise synchrony. This produces time-averaged values that are consistent with the ISCs in the regions. In contrast to a time-invariant phasor, an analytic signal has a time-varying amplitude envelope and frequency and can thus be used to track changes in synchrony over time. However, for meaningful separation of the envelope and phase of the signal, the original signal has to be contained in a limited frequency band, which can be obtained through band-pass filtering. The smaller this frequency band is, the better the amplitude envelope is separated into a lower frequency than the phase of the signal in the pass-band (Glerean et al., 2012). However, poorly designed filters may affect the shape of the signal considerably and in extreme cases even remove the signal of interest. For example, some filters can cause non-linear phase shifts across the frequency spectrum, or excessively tight pass-band may miss important frequencies completely.
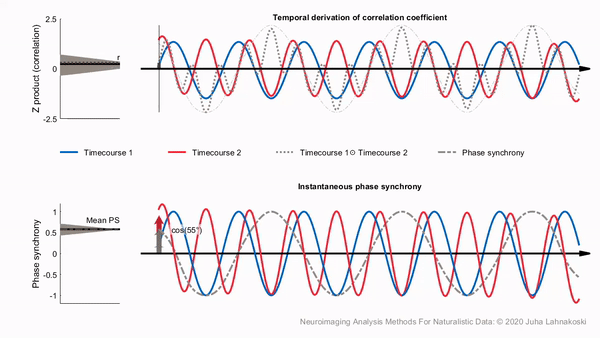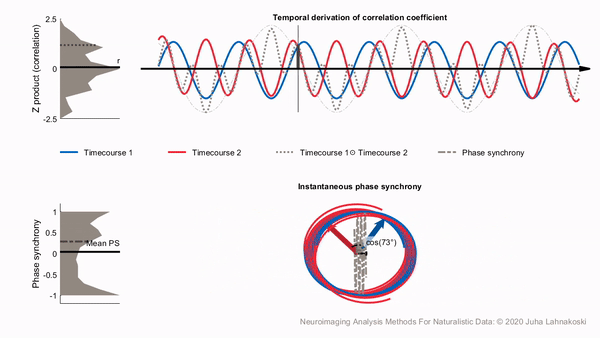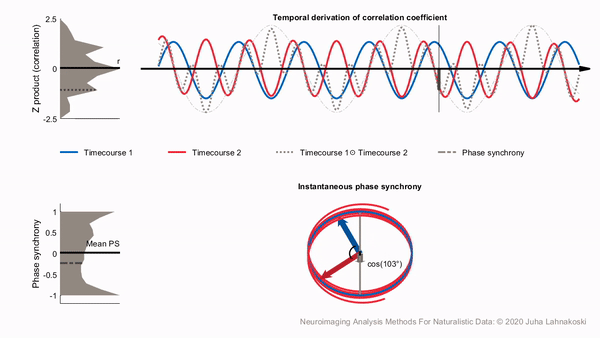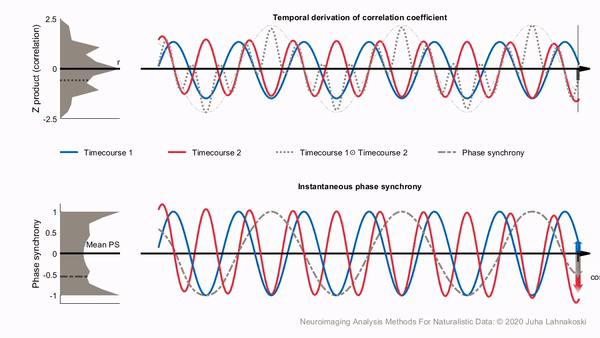
Compared to sliding-window correlations, phase synchronization has the benefit that no explicit time windowing is required and synchronization is estimated at the original sampling frequency of the signals (though you still do need to choose a specific narrow frequency band). However, in a single pairwise comparison, phase synchrony can get extreme values by chance, much like a stopped clock that shows the right time twice a day. This is illustrated in the bottom panel of the animation. Despite the two signals being independent, the histogram on the left shows that many of the time points have extreme synchrony values. Accordingly, the estimate of mean synchrony oscillates with the phase of the signals, until eventually stabilizing around zero as expected for independent signals. Thus, phase synchrony of two signals has the potential of producing extreme synchrony values much like time windowed correlations. This can be mitigated by averaging. Averaging over the timepoints of a full session, intersubject phase synchronization (ISPS) of regional activity produces highly similar group-level results to ISC. However, this removes the benefit of the temporal accuracy of ISPS and is thus of limited use. By contrast, averaging over (pairs of) subjects improves the reliability of synchrony in a larger population while retaining the temporal accuracy.
Intersubject Phase Synchrony Tutorial¶
Now, let’s start working through some code to build an intuition for the core concepts behind intersubject phase synchrony (ISPS). We will begin by creating an animation of the phase angles.
First, we need to compute the instantaneous phase angle of our average ROI activity for each subject. We will use an infinite impulse response (IIR) bandpass butterworth filter. This requires specifying the sampling_frequency in cycles per second (i.e., Hz), which is \(\frac{1}{tr}\), and lower and upper cutoff frequencies also in Hz. We will then apply a hilbert transform and extract the phase angle for each time point.
Let’s extract signal from primary auditory cortex, which we can assume will synchronize strongly across participants (roi=35) and use a lower bound cutoff frequency of 0.04Hz and an upper bound of 0.07Hz as recommended by (Glerean et al., 2012).
To visualize the data, we will plot 100 TRs of each participant’s phase angles from the auditory cortex using a polar plot. Notice that for some time points all subjects have a different phase angle. These time points should have low synchrony values (i.e., resultant vector length close to zero). Other time points the phase angles will cluster together and all face the same direction. These time points will have high phase synchrony (i.e., resultant vector length close to one). We can also compute the mean phase angle for the group using circular statistics (red line). We don’t actually care so much about the mean angle, but rather the length of the resultant vector. The resultant vector length is our metric of intersubject phase clustering, or the degree to which participants are in phase with each other at a given time point. Notice how the length gets shorter the more participants are out of phase and longer when they are all facing the same direction.
roi = 35
tr = 1.5
lowcut = .04
highcut = .07
phase_angles = np.angle(hilbert(_butter_bandpass_filter(get_subject_roi(sub_timeseries, roi), lowcut, highcut, 1/tr), axis=0))
xs, ys = [], []
fig = plt.figure(constrained_layout=False, figsize=(10,10))
spec = gridspec.GridSpec(ncols=4, nrows=4, figure=fig)
a0 = fig.add_subplot(spec[:2, :2], projection='polar')
plt.polar([0, _phase_mean_angle(phase_angles[0,:])], [0,1], color='red', linewidth=3)
a1 = fig.add_subplot(spec[:2, 2:4], projection='polar')
plt.polar([0, phase_angles[0,0]], [0,1], color='navy', linewidth=1, alpha=.2)
a2 = fig.add_subplot(spec[2:, :])
a2.plot(_phase_vector_length(phase_angles))
a2.set_ylabel('Phase Synchrony', fontsize=18)
a2.set_xlabel('Time (TRs)', fontsize=18)
def animate(i, xs, ys):
xs = np.linspace(0, i, i+1, endpoint=True)
ys = phase_angles[:i+1, :]
a0.clear()
a0.plot([0, _phase_mean_angle(phase_angles[i,:])], [0, _phase_vector_length(phase_angles[i,:])], color='red', linewidth=3)
a0.set_title('Mean Phase Angle', fontsize=18)
a0.set_ylim([0,1])
a1.clear()
for j in range(ys.shape[1]):
a1.plot([0, phase_angles[i,j]], [0,1], color='navy', alpha=.5)
a1.set_title('Subject Phase Angles', fontsize=18)
a2.clear()
a2.plot(xs, _phase_vector_length(ys))
a2.set_ylim([0,1])
a2.set_ylabel('Resultant Vector Length', fontsize=18)
a2.set_xlabel('Time (TRs)', fontsize=18)
a2.set_title('Intersubject Phase Synchrony', fontsize=18)
plt.tight_layout()
animation = FuncAnimation(fig, animate, fargs=(xs, ys), frames=range(100,200), interval=100, blit=False)
plt.close(animation._fig)
HTML(animation.to_jshtml())