Visualizing High Dimensional Data¶
Written by Jeremy Manning
The HyperTools Python toolbox provides tools for gaining “geometric insights” into high-dimensional multi-subject datasets. The overarching idea of the toolbox is to use a series of data processing and visualization approaches to turn a dataset into a 2D or 3D shape or animation that reflects key properties of the original dataset. This can be a useful way to gain intuitions about a dataset, since our visual systems are adept at identifying complex patterns in visual data. In this tutorial we will use HyperTools to visualize some neural and behavioral data.
The HyperTools data visualization pipeline¶
At its core, the HyperTools toolbox provides a suite of wrappers for myriad functions in the scikit-learn, pymvpa, braniak, and seaborn toolboxes, among others. A short JMLR paper describing the HyperTools analysis pipeline may be found here, and a long-form preprint with additional details may be found here. This repository also contains additional example notebooks. If you are looking for an alternative introduction to the toolbox with some additional demos, you may be interested in this video:
from IPython.display import YouTubeVideo
YouTubeVideo('hb_ER9RGtOM')
The HyperTools data visualization pipeline defines a set of heuristics for preprocessing a high-dimensional multi-subject dataset and generating a visualization that may be used to gain useful insights into the data. The idea is to generate visualizable 2D and 3D shapes and animations that reflect key properties of the data. For example, this visualization displays several participants’ unfolding neural patterns as they listen to a 10-minute story (here each line represents the neural activity patterns of a single person):

The pipeline comprises the following steps:
Wrangle the dataset into a list of numerical matrices (one matrix per subject). The matrices’ rows denote timepoints and their columns denote features (a feature may be a voxel, electrode, a word embedding dimension, a label or category, or some other set of observable or quantifiable values). Note that, for some data types, this wrangling process is non-trivial. HyperTools incorporates useful functions for parsing a variety of datatypes, including text data. The pliers toolbox may also be used to generate HyperTools-compatable feature vectors for a wider range of datatypes.
Normalize (z-score) within each matrix column to ensure that all dimensions have equal representation in the final visualization. (This step is optional.) Pad matrices with columns of zeros as needed, to ensure they all have the same number of columns (\(k\)). Note that all matrices must have the same number of rows (number of rows/timepoints: \(t\)).
Hyperalign the matrices into a common space.
Embed the hyperaligned data into a low-dimensional space (typically this space will be either 2D or 3D).
Generate a plot or animation of the reduced data.
If a dataset is stored in the list data, the HyperTools pipeline may be used to generate a visualization using a single command:
import hypertools as hyp
hyp.plot(data)
Getting Started¶
Before getting started with this tutorial, we need to make sure you have the necessary software installed and data downloaded.
Software¶
This tutorial requires the following Python packages to be installed. See the Software Installation tutorial for more information.
hypertools
timecorr
seaborn
matplotlib
numpy
pandas
scipy
nltools
nilearn
datalad
Let’s now load the modules we will be using for this tutorial.
import os
from glob import glob as lsdir
import numpy as np
import pandas as pd
from scipy.interpolate import pchip
from nltools.mask import create_sphere, expand_mask
from nltools.data import Brain_Data, Adjacency
from nilearn.plotting import plot_stat_map
import datalad.api as dl
import hypertools as hyp
import seaborn as sns
import timecorr as tc
import warnings
warnings.simplefilter('ignore')
%matplotlib inline
Data¶
This tutorial will be using the Sherlock dataset and will require downloading the cropped and denoised hdf5 files, the annotations file Sherlock_Segments_1000_NN_2017.xlsx, and the preprocessed video text file video_text.npy.
You will want to change datadir to wherever you have installed the Sherlock datalad repository (e.g. ~/data). We will initialize a datalad dataset instance and get the files we need for this tutorial. If you’ve already downloaded everything, this cell should execute quickly. See the Download Data Tutorial for more information about how to install and use datalad.
datadir = '/Volumes/Engram/Data/Sherlock'
# If dataset hasn't been installed, clone from GIN repository
if not os.path.exists(datadir):
dl.clone(source='https://gin.g-node.org/ljchang/Sherlock', path=datadir)
# Initialize dataset
ds = dl.Dataset(datadir)
# Get Cropped & Denoised HDF5 Files
result = ds.get(lsdir(os.path.join(datadir, 'fmriprep', '*', 'func', '*crop*hdf5')))
# Get Annotation File
result = ds.get(os.path.join(datadir, 'onsets', 'Sherlock_Segments_1000_NN_2017.xlsx'))
# Get Preprocessed Video Text
result = ds.get(os.path.join(datadir, 'stimuli', 'video_text.npy'))
ROI responses while viewing Sherlock¶
Following the functional alignment tutorial, we’ll select out voxels in early visual cortex from the Sherlock dataset. We’ll also examine primary auditory cortex and motor cortex responses. Then we’ll apply the HyperTools pipeline to the dataset and visualize the responses within each ROI as a 3D image. Note you could also work with the Average ROI csv files as we did with the Dynamic Correlation tutorial. Here, we will load the full dataset and manually extract ROIs.
mask = Brain_Data('https://neurovault.org/media/images/8423/k50_2mm.nii.gz')
vectorized_mask = expand_mask(mask)
mask.plot()

rois = pd.read_csv('https://raw.githubusercontent.com/naturalistic-data-analysis/tutorial_development/master/hypertools/rois.csv', header=None, names=['ID', 'Region'])
rois.head()
| ID | Region | |
|---|---|---|
| 0 | 0 | Anterior MPFC |
| 1 | 1 | Fusiform/parahippocampus |
| 2 | 2 | DMPFC |
| 3 | 3 | Sensorimotor/postcentral gyrus |
| 4 | 4 | V1 |
roi_names = ['V1', 'A1', 'Precentral gyrus']
roi_ids = [int(rois.query(f'Region == "{r}"')['ID']) for r in roi_names]
my_rois = {k:v for k, v in zip(roi_names, roi_ids)}
# load subject's data and extract roi
data2 = {}
for run in ['Part1', 'Part2']:
file_list = lsdir(os.path.join(datadir, 'fmriprep', '*', 'func', f'*crop*{run}*hdf5'))
all_sub_roi = {}
for f_name in file_list:
sub_dat = Brain_Data(f_name)
sub = os.path.basename(f_name).split('_')[0]
print(sub, run)
sub_roi = {}
for roi in my_rois:
sub_roi[roi] = [sub_dat.apply_mask(vectorized_mask[my_rois[roi]])]
all_sub_roi[sub] = sub_roi
data2[run] = all_sub_roi
# rearrange data into new dictionary
data = {}
for run in data2.keys():
sub_list = list(data2[run].keys())
sub_list.sort()
roi_dat = {}
for roi in my_rois:
sub_roi = []
for sub in sub_list:
sub_roi.append(data2[run][sub][roi][0])
roi_dat[roi] = sub_roi
data[run] = roi_dat
del data2
sub-01 Part1
sub-02 Part1
sub-03 Part1
sub-04 Part1
sub-05 Part1
sub-06 Part1
sub-07 Part1
sub-08 Part1
sub-09 Part1
sub-10 Part1
sub-11 Part1
sub-12 Part1
sub-13 Part1
sub-14 Part1
sub-15 Part1
sub-16 Part1
sub-01 Part2
sub-02 Part2
sub-03 Part2
sub-04 Part2
sub-05 Part2
sub-06 Part2
sub-07 Part2
sub-08 Part2
sub-09 Part2
sub-10 Part2
sub-11 Part2
sub-12 Part2
sub-13 Part2
sub-14 Part2
sub-15 Part2
sub-16 Part2
Getting some intuitions for the Sherlock data using HyperTools¶
Examining brain responses in visual, auditory, and motor cortex during movie watching¶
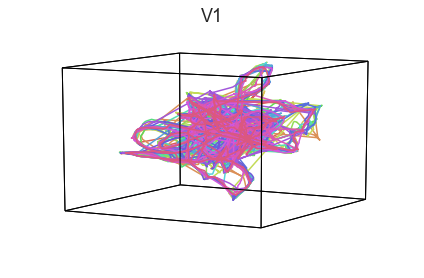
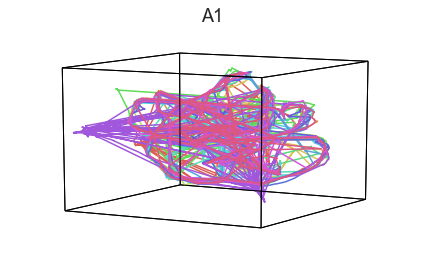
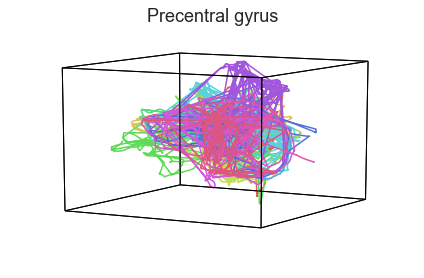
Participants in the Sherlock experiment all watched the same audiovisual movie. Therefore, to the extent that participants’ brain responses were driven by the movie, we might expect that their brain responses in primary auditory and visual cortex should follow similar or related patterns. In contrast, non-sensory regions like primary motor cortex should not show this sort of agreement.
We can test this intuition qualitatively by projecting the ROI data from visual, auditory, and motor cortex into a shared low-dimensional space. Each participant’s trajectory will be plotted in a different color. Regions that show greater agreement across participants will have more similarly shaped (overlapping) trajectories when plotted using the HyperTools pipeline.
def plot_aligned_ROI_trajectories(data, reduce='UMAP', align='hyper', n_iter=5, ndims=500, internal_reduce='IncrementalPCA', **kwargs):
if type(data) == dict:
for r in data.keys(): #roi
plot_aligned_ROI_trajectories(data[r], reduce=reduce, align=align, ndims=ndims, internal_reduce=internal_reduce, title=r, **kwargs)
else:
#step 1: reduce dataset before aligning (runs much faster)
reduced_data = hyp.reduce([x.data for x in data], reduce=internal_reduce, ndims=ndims)
#step 2: smooth trajectories so they look prettier
smoothed_data = tc.smooth(reduced_data, kernel_fun=tc.helpers.gaussian_weights, kernel_params={'var': 500})
#step 3: align trajectories
aligned_data = smoothed_data
for i in range(n_iter):
aligned_data = hyp.align(aligned_data, align=align)
#now generate a plot
hyp.plot(aligned_data, reduce=reduce, **kwargs)
plot_aligned_ROI_trajectories(data['Part1'])
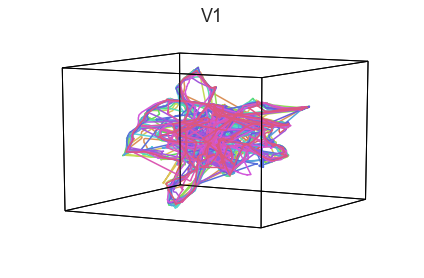
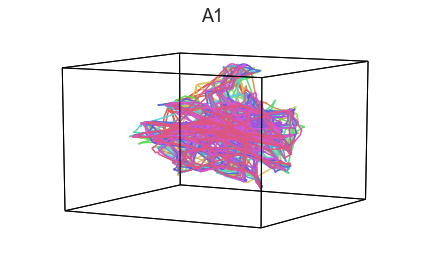
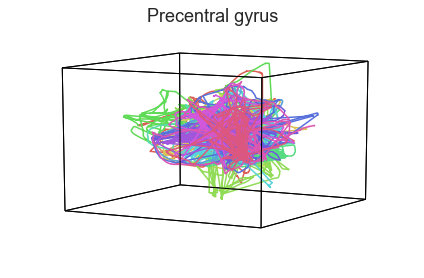
We can see strong agreement across people in V1 and A1, whereas precentral gyrus responses are much more variable. Now let’s see if these patterns also hold for the second half of the dataset:
plot_aligned_ROI_trajectories(data['Part2'])
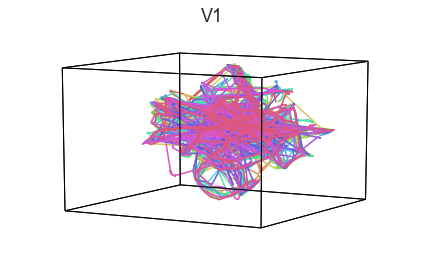
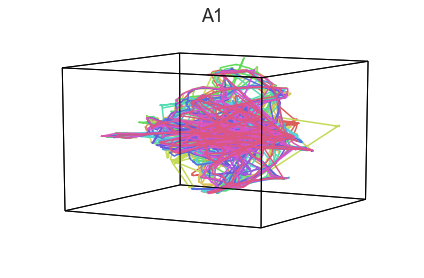
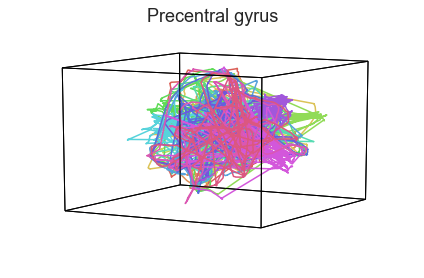
It looks like this pattern holds! To test this idea formally, we could develop a measure of trajectory consistency across people (e.g. mean squared error between the corresponding timepoints, across all pairs of participants’ trajectories). We could also explore the extent to which different brain regions exhibit consistent patterns across people.
Using different embedding spaces to obtain a more complete sense of high-dimensional space¶
When we visualize high-dimensional data as 3D shapes, we necessarily lose information. One strategy for getting a better sense of the “true shape” of the data is to use different projection algorithms for embedding the data into the 3D space (this may be done using the reduce keyword).
first_roi = list(data['Part1'].keys())[0]
plot_aligned_ROI_trajectories(data['Part1'][first_roi], align='hyper', reduce='IncrementalPCA', title=f'{first_roi}: Incremental PCA')
plot_aligned_ROI_trajectories(data['Part1'][first_roi], align='hyper', reduce='MiniBatchDictionaryLearning', title=f'{first_roi}: Mini batch dictionary learning')
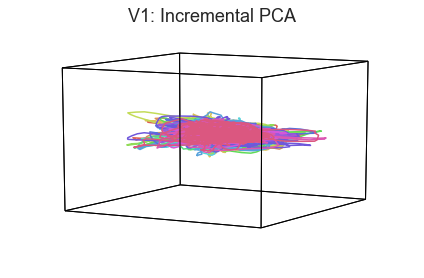
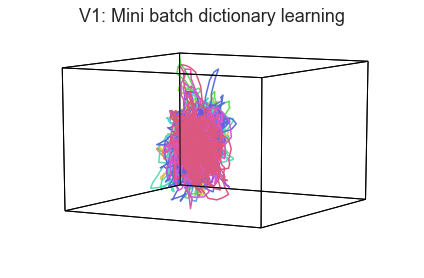
In both of these examples we can still see the high degree of consistency across people. Each embedding approach amplifies preserves or emphasizes a different set of properties from the original high-dimensional feature space.
Aligning using the shared response model¶
The above examples use hyperalignment to map different participants’ data into a common space. HyperTools also supports alignment using the Shared Response Model (SRM):
plot_aligned_ROI_trajectories(data['Part1'], align='SRM')
What is the “shape” of the Sherlock episode?¶
Following an approach similar to the one used in Heusser et al., 2018, we can use also HyperTools to examine how the content of the Sherlock episode unfolds. Whereas the analyses above show how HyperTools may be used to gain insight into dynamics in neural data, we can also use HyperTools to examine how the semantic content of the episode changes over time. We’ll fit a word embedding model to a set of detailed annotations of each scene in the episode.
First, let’s download the annotations to get a sense of what they’re like.
annotations = pd.read_excel(os.path.join(datadir, 'onsets', 'Sherlock_Segments_1000_NN_2017.xlsx'))
annotations.head(3)
| Segment Number | Start Time (s) | End Time (s) | Start Time (TRs, 1.5s) | End Time (TRs, 1.5s) | Scene_Segment | Scene_Name | Scene Details - A Level | Space-In/Outdoor | Name - All | ... | Music Presence | Words on Screen | Arousal - Rater 1 | Valence - Rater 1 | Arousal - Rater 2 | Valence - Rater 2 | Arousal - Rater 3 | Valence - Rater 3 | Arousal - Rater 4 | Valence - Rater 4 | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 0 | 1 | 0 | 12 | 1.0 | 8.0 | 1 | Cartoon | People in popcorn, candy, and soft drink costu... | Indoor | Cartoon People in Costumes | ... | Yes | NaN | 3 | + | 1 | + | 2 | + | 3 | + |
| 1 | 2 | 12 | 15 | 9.0 | 10.0 | 1 | Cartoon | Popcorn is being popped in a large popcorn mac... | Indoor | Female Singer | ... | Yes | NaN | 3 | + | 1 | + | 2 | + | 2 | + |
| 2 | 3 | 15 | 17 | 11.0 | 11.0 | 1 | Cartoon | Men sing in reply: "the popcorn can't be beat!" | Indoor | Male Singers | ... | Yes | NaN | 3 | + | 1 | + | 2 | + | 2 | + |
3 rows × 24 columns
Next, we’ll preprocess the anotations in sliding windows of (up to) 50 segments. In each sliding window, we’ll concatenate all of the text into a single “blob” that merges all of the columns of the annotation spreadsheet, from all of the segments in that window. Note that the preprocessing was carried out using the code in this notebook; here we’ll be downloading the resulting preprocessed text rather than reproducing it.
text = np.load(os.path.join(datadir, 'stimuli', 'video_text.npy'))
Let’s examine the text in a window somewhere near the middle:
text[500][:250] + '...'
'sherlock takes a deep breath through his nose outdoor sherlock donovan sherlock lauriston gardens street over the shoulder medium no sherlock i even know you didnt make it home last night outdoor sherlock donovan sherlock sherlock lauriston gardens...'
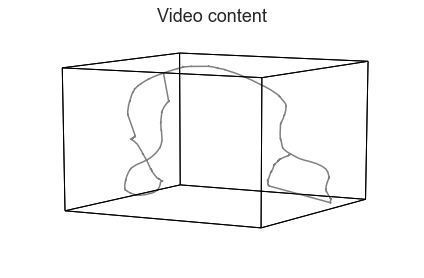
Next, we’ll use HyperTools to train a topic model (Blei et al., 2003) on the annotations, treating the text in each sliding window as a document. We’ll plot the result as a 3D shape. (For an example of an alternative word embedding model, see the Natural Language Processing tutorial.)
text_geometry = hyp.plot(text, reduce='UMAP', color='gray', title='Video content')
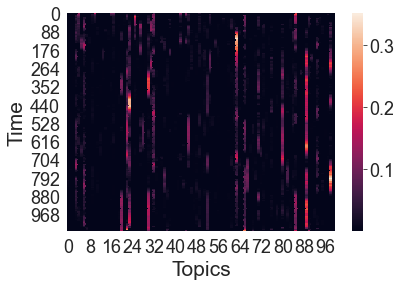
We can also visualize the timecourse of word embeddings for the movie as a heatmap. Since we’ve already fit our topic model to the annotation text, HyperTools automatically uses the cached result (so the command runs quickly). Here each row is a timepoint and each column is a topic dimension (i.e., a word embedding dimension):
topics = text_geometry.get_formatted_data()[0]
h = sns.heatmap(topics)
h.set_xlabel('Topics')
h.set_ylabel('Time')
Further reading¶
For more in-depth explorations of the Sherlock data using HyperTools, check out this paper along with the associated code and data. For more in-depth HyperTools tutorials, take a look here. This repository contains additional example applications of HyperTools to a variety of different data types.
Contributions¶
Jeremy Manning developed the initial notebook. Luke Chang tested and edited code.