Introduction to Neuroimaging Data¶
Written by Luke Chang & Sasha Brietzke
In this tutorial we will learn the basics of the organization of data folders, and how to load, plot, and manipulate neuroimaging data in Python.
To introduce the basics of fMRI data structures, watch this short video by Martin Lindquist.
from IPython.display import YouTubeVideo
YouTubeVideo('OuRdQJMU5ro')
Software Packages¶
There are many different software packages to analyze neuroimaging data. Most of them are open source and free to use (with the exception of BrainVoyager). The most popular ones (SPM, FSL, & AFNI) have been around a long time and are where many new methods are developed and distributed. These packages have focused on implementing what they believe are the best statistical methods, ease of use, and computational efficiency. They have very large user bases so many bugs have been identified and fixed over the years. There are also lots of publicly available documentation, listserves, and online tutorials, which makes it very easy to get started using these tools.
There are also many more boutique packages that focus on specific types of preprocessing step and analyses such as spatial normalization with ANTs, connectivity analyses with the conn-toolbox, representational similarity analyses with the rsaToolbox, and prediction/classification with pyMVPA.
Many packages have been developed within proprietary software such as Matlab (e.g., SPM, Conn, RSAToolbox, etc). Unfortunately, this requires that your university has site license for Matlab and many individual add-on toolboxes. If you are not affiliated with a University, you may have to pay for Matlab, which can be fairly expensive. There are free alternatives such as octave, but octave does not include many of the add-on toolboxes offered by matlab that may be required for a specific package. Because of this restrictive licensing, it is difficult to run matlab on cloud computing servers and to use with free online courses such as dartbrains. Other packages have been written in C/C++/C# and need to be compiled to run on your specific computer and operating system. While these tools are typically highly computationally efficient, it can sometimes be challenging to get them to install and work on specific computers and operating systems.
There has been a growing trend to adopt the open source Python framework in the data science and scientific computing communities, which has lead to an explosion in the number of new packages available for statistics, visualization, machine learning, and web development. pyMVPA was an early leader in this trend, and there are many great tools that are being actively developed such as nilearn, brainiak, neurosynth, nipype, fmriprep, and many more. One exciting thing is that these newer developments have built on the expertise of decades of experience with imaging analyses, and leverage changes in high performance computing. There is also a very tight integration with many cutting edge developments in adjacent communities such as machine learning with scikit-learn, tensorflow, and pytorch, which has made new types of analyses much more accessible to the neuroimaging community. There has also been an influx of younger contributors with software development expertise. You might be surprised to know that many of the popular tools being used had core contributors originating from the neuroimaging community (e.g., scikit-learn, seaborn, and many more).
For this course, I have chosen to focus on tools developed in Python as it is an easy to learn programming language, has excellent tools, works well on distributed computing systems, has great ways to disseminate information (e.g., jupyter notebooks, jupyter-book, etc), and is free! If you are just getting started, I would spend some time working with NiLearn and Brainiak, which have a lot of functionality, are very well tested, are reasonably computationally efficient, and most importantly have lots of documentation and tutorials to get started.
We will be using many packages throughout the course such as PyBids to navigate neuroimaging datasets, fmriprep to perform preprocessing, and nltools, which is a package developed in my lab, to do basic data manipulation and analysis. NLtools is built using many other toolboxes such as nibabel and nilearn, and we will also be using these frequently throughout the course.
BIDS: Brain Imaging Dataset Specification¶
Recently, there has been growing interest to share datasets across labs and even on public repositories such as openneuro. In order to make this a succesful enterprise, it is necessary to have some standards in how the data are named and organized. Historically, each lab has used their own idiosyncratic conventions, which can make it difficult for outsiders to analyze. In the past few years, there have been heroic efforts by the neuroimaging community to create a standardized file organization and naming practices. This specification is called BIDS for Brain Imaging Dataset Specification.
As you can imagine, individuals have their own distinct method of organizing their files. Think about how you keep track of your files on your personal laptop (versus your friend). This may be okay in the personal realm, but in science, it’s best if anyone (especially yourself 6 months from now!) can follow your work and know which files mean what by their titles.
Here’s an example of non-Bids versus BIDS dataset found in this paper:
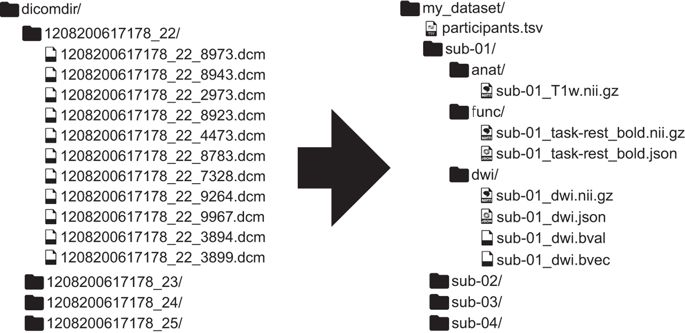
Here are a few major differences between the two datasets:
In BIDS, files are in nifti format (not dicoms).
In BIDS, scans are broken up into separate folders by type of scan(functional versus anatomical versus diffusion weighted) for each subject.
In BIDS, JSON files are included that contain descriptive information about the scans (e.g., acquisition parameters)
Not only can using this specification be useful within labs to have a set way of structuring data, but it can also be useful when collaborating across labs, developing and utilizing software, and publishing data.
In addition, because this is a consistent format, it is possible to have a python package to make it easy to query a dataset. We recommend using pybids.
The dataset we will be working with has already been converted to the BIDS format (see download localizer tutorial).
You may need to install pybids to query the BIDS datasets using following command !pip install pybids.
The BIDSLayout¶
Pybids is a package to help query and navigate a neurogimaging dataset that is in the BIDs format. At the core of pybids is the BIDSLayout object. A BIDSLayout is a lightweight Python class that represents a BIDS project file tree and provides a variety of helpful methods for querying and manipulating BIDS files. While the BIDSLayout initializer has a large number of arguments you can use to control the way files are indexed and accessed, you will most commonly initialize a BIDSLayout by passing in the BIDS dataset root location as a single argument.
Notice we are setting derivatives=True. This means the layout will also index the derivatives sub folder, which might contain preprocessed data, analyses, or other user generated files.
from bids import BIDSLayout, BIDSValidator
import os
data_dir = '../data/localizer'
layout = BIDSLayout(data_dir, derivatives=True)
layout
BIDS Layout: ...pbox/Dartbrains/Data/localizer | Subjects: 94 | Sessions: 0 | Runs: 0
When we initialize a BIDSLayout, all of the files and metadata found under the specified root folder are indexed. This can take a few seconds (or, for very large datasets, a minute or two). Once initialization is complete, we can start querying the BIDSLayout in various ways. The main query method is .get(). If we call .get() with no additional arguments, we get back a list of all the BIDS files in our dataset.
Let’s return the first 10 files
layout.get()[:10]
[<BIDSJSONFile filename='/Users/lukechang/Dropbox/Dartbrains/Data/localizer/dataset_description.json'>,
<BIDSFile filename='/Users/lukechang/Dropbox/Dartbrains/Data/localizer/derivatives/fmriprep/.DS_Store'>,
<BIDSJSONFile filename='/Users/lukechang/Dropbox/Dartbrains/Data/localizer/derivatives/fmriprep/dataset_description.json'>,
<BIDSFile filename='/Users/lukechang/Dropbox/Dartbrains/Data/localizer/derivatives/fmriprep/logs/CITATION.bib'>,
<BIDSFile filename='/Users/lukechang/Dropbox/Dartbrains/Data/localizer/derivatives/fmriprep/logs/CITATION.html'>,
<BIDSFile filename='/Users/lukechang/Dropbox/Dartbrains/Data/localizer/derivatives/fmriprep/logs/CITATION.md'>,
<BIDSFile filename='/Users/lukechang/Dropbox/Dartbrains/Data/localizer/derivatives/fmriprep/logs/CITATION.tex'>,
<BIDSFile filename='/Users/lukechang/Dropbox/Dartbrains/Data/localizer/derivatives/fmriprep/sub-S01.html'>,
<BIDSFile filename='/Users/lukechang/Dropbox/Dartbrains/Data/localizer/derivatives/fmriprep/sub-S01/.DS_Store'>,
<BIDSJSONFile filename='/Users/lukechang/Dropbox/Dartbrains/Data/localizer/derivatives/fmriprep/sub-S01/anat/sub-S01_desc-brain_mask.json'>]
As you can see, just a generic .get() call gives us all of the files. We will definitely want to be a bit more specific. We can specify the type of data we would like to query. For example, suppose we want to return the first 10 subject ids.
layout.get(target='subject', return_type='id')[:10]
['S01', 'S02', 'S03', 'S04', 'S05', 'S06', 'S07', 'S08', 'S09', 'S10']
Or perhaps, we would like to get the file names for the raw bold functional nifti images for the first 10 subjects. We can filter files in the raw or derivatives, using scope keyword.scope='raw', to only query raw bold nifti files.
layout.get(target='subject', scope='raw', suffix='bold', return_type='file')[:10]
['/Users/lukechang/Dropbox/Dartbrains/Data/localizer/sub-S01/func/sub-S01_task-localizer_bold.nii.gz',
'/Users/lukechang/Dropbox/Dartbrains/Data/localizer/sub-S02/func/sub-S02_task-localizer_bold.nii.gz',
'/Users/lukechang/Dropbox/Dartbrains/Data/localizer/sub-S03/func/sub-S03_task-localizer_bold.nii.gz',
'/Users/lukechang/Dropbox/Dartbrains/Data/localizer/sub-S04/func/sub-S04_task-localizer_bold.nii.gz',
'/Users/lukechang/Dropbox/Dartbrains/Data/localizer/sub-S05/func/sub-S05_task-localizer_bold.nii.gz',
'/Users/lukechang/Dropbox/Dartbrains/Data/localizer/sub-S06/func/sub-S06_task-localizer_bold.nii.gz',
'/Users/lukechang/Dropbox/Dartbrains/Data/localizer/sub-S07/func/sub-S07_task-localizer_bold.nii.gz',
'/Users/lukechang/Dropbox/Dartbrains/Data/localizer/sub-S08/func/sub-S08_task-localizer_bold.nii.gz',
'/Users/lukechang/Dropbox/Dartbrains/Data/localizer/sub-S09/func/sub-S09_task-localizer_bold.nii.gz',
'/Users/lukechang/Dropbox/Dartbrains/Data/localizer/sub-S10/func/sub-S10_task-localizer_bold.nii.gz']
When you call .get() on a BIDSLayout, the default returned values are objects of class BIDSFile. A BIDSFile is a lightweight container for individual files in a BIDS dataset.
Here are some of the attributes and methods available to us in a BIDSFile (note that some of these are only available for certain subclasses of BIDSFile; e.g., you can’t call get_image() on a BIDSFile that doesn’t correspond to an image file!):
.path: The full path of the associated file
.filename: The associated file’s filename (without directory)
.dirname: The directory containing the file
.get_entities(): Returns information about entities associated with this BIDSFile (optionally including metadata)
.get_image(): Returns the file contents as a nibabel image (only works for image files)
.get_df(): Get file contents as a pandas DataFrame (only works for TSV files)
.get_metadata(): Returns a dictionary of all metadata found in associated JSON files
.get_associations(): Returns a list of all files associated with this one in some way
Let’s explore the first file in a little more detail.
f = layout.get()[0]
f
<BIDSJSONFile filename='/Users/lukechang/Dropbox/Dartbrains/Data/localizer/dataset_description.json'>
If we wanted to get the path of the file, we can use .path.
f.path
'/Users/lukechang/Dropbox/Dartbrains/Data/localizer/dataset_description.json'
Suppose we were interested in getting a list of tasks included in the dataset.
layout.get_task()
['localizer']
We can query all of the files associated with this task.
layout.get(task='localizer', suffix='bold', scope='raw')[:10]
[<BIDSImageFile filename='/Users/lukechang/Dropbox/Dartbrains/Data/localizer/sub-S01/func/sub-S01_task-localizer_bold.nii.gz'>,
<BIDSImageFile filename='/Users/lukechang/Dropbox/Dartbrains/Data/localizer/sub-S02/func/sub-S02_task-localizer_bold.nii.gz'>,
<BIDSImageFile filename='/Users/lukechang/Dropbox/Dartbrains/Data/localizer/sub-S03/func/sub-S03_task-localizer_bold.nii.gz'>,
<BIDSImageFile filename='/Users/lukechang/Dropbox/Dartbrains/Data/localizer/sub-S04/func/sub-S04_task-localizer_bold.nii.gz'>,
<BIDSImageFile filename='/Users/lukechang/Dropbox/Dartbrains/Data/localizer/sub-S05/func/sub-S05_task-localizer_bold.nii.gz'>,
<BIDSImageFile filename='/Users/lukechang/Dropbox/Dartbrains/Data/localizer/sub-S06/func/sub-S06_task-localizer_bold.nii.gz'>,
<BIDSImageFile filename='/Users/lukechang/Dropbox/Dartbrains/Data/localizer/sub-S07/func/sub-S07_task-localizer_bold.nii.gz'>,
<BIDSImageFile filename='/Users/lukechang/Dropbox/Dartbrains/Data/localizer/sub-S08/func/sub-S08_task-localizer_bold.nii.gz'>,
<BIDSImageFile filename='/Users/lukechang/Dropbox/Dartbrains/Data/localizer/sub-S09/func/sub-S09_task-localizer_bold.nii.gz'>,
<BIDSImageFile filename='/Users/lukechang/Dropbox/Dartbrains/Data/localizer/sub-S10/func/sub-S10_task-localizer_bold.nii.gz'>]
Notice that there are nifti and event files. We can get the filename for the first particant’s functional run
f = layout.get(task='localizer')[0].filename
f
'sub-S01_task-localizer_desc-carpetplot_bold.svg'
If you want a summary of all the files in your BIDSLayout, but don’t want to have to iterate BIDSFile objects and extract their entities, you can get a nice bird’s-eye view of your dataset using the to_df() method.
layout.to_df()
| entity | path | datatype | extension | subject | suffix | task |
|---|---|---|---|---|---|---|
| 0 | /Users/lukechang/Dropbox/Dartbrains/Data/local... | NaN | json | NaN | description | NaN |
| 1 | /Users/lukechang/Dropbox/Dartbrains/Data/local... | NaN | json | NaN | participants | NaN |
| 2 | /Users/lukechang/Dropbox/Dartbrains/Data/local... | NaN | tsv | NaN | participants | NaN |
| 3 | /Users/lukechang/Dropbox/Dartbrains/Data/local... | NaN | tsv | NaN | behavioural | NaN |
| 4 | /Users/lukechang/Dropbox/Dartbrains/Data/local... | NaN | tsv | NaN | subject | NaN |
| ... | ... | ... | ... | ... | ... | ... |
| 284 | /Users/lukechang/Dropbox/Dartbrains/Data/local... | anat | nii.gz | S94 | T1w | NaN |
| 285 | /Users/lukechang/Dropbox/Dartbrains/Data/local... | func | nii.gz | S94 | bold | localizer |
| 286 | /Users/lukechang/Dropbox/Dartbrains/Data/local... | func | tsv | S94 | events | localizer |
| 287 | /Users/lukechang/Dropbox/Dartbrains/Data/local... | NaN | json | NaN | bold | localizer |
| 288 | /Users/lukechang/Dropbox/Dartbrains/Data/local... | NaN | NaN | NaN | NaN | NaN |
289 rows × 6 columns
Loading Data with Nibabel¶
Neuroimaging data is often stored in the format of nifti files .nii which can also be compressed using gzip .nii.gz. These files store both 3D and 4D data and also contain structured metadata in the image header.
There is an very nice tool to access nifti data stored on your file system in python called nibabel. If you don’t already have nibabel installed on your computer it is easy via pip. First, tell the jupyter cell that you would like to access the unix system outside of the notebook and then install nibabel using pip !pip install nibabel. You only need to run this once (unless you would like to update the version).
nibabel objects can be initialized by simply pointing to a nifti file even if it is compressed through gzip. First, we will import the nibabel module as nib (short and sweet so that we don’t have to type so much when using the tool). I’m also including a path to where the data file is located so that I don’t have to constantly type this. It is easy to change this on your own computer.
We will be loading an anatomical image from subject S01 from the localizer dataset. See this paper for more information about this dataset.
We will use pybids to grab subject S01’s T1 image.
import nibabel as nib
data = nib.load(layout.get(subject='S01', scope='derivatives', suffix='T1w', return_type='file', extension='nii.gz')[1])
If we want to get more help on how to work with the nibabel data object we can either consult the documentation or add a ?.
data?
The imaging data is stored in either a 3D or 4D numpy array. Just like numpy, it is easy to get the dimensions of the data using shape.
data.shape
(193, 229, 193)
Looks like there are 3 dimensions (x,y,z) that is the number of voxels in each dimension. If we know the voxel size, we could convert this into millimeters.
We can also directly access the data and plot a single slice using standard matplotlib functions.
%matplotlib inline
import matplotlib.pyplot as plt
plt.imshow(data.get_fdata()[:,:,50])
<matplotlib.image.AxesImage at 0x7fadc1706e50>
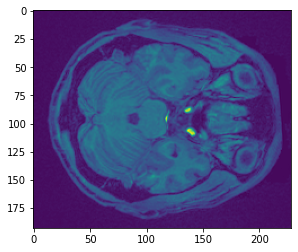
Try slicing different dimensions (x,y,z) yourself to get a feel for how the data is represented in this anatomical image.
We can also access data from the image header. Let’s assign the header of an image to a variable and print it to view it’s contents.
header = data.header
print(header)
<class 'nibabel.nifti1.Nifti1Header'> object, endian='<'
sizeof_hdr : 348
data_type : b''
db_name : b''
extents : 0
session_error : 0
regular : b'r'
dim_info : 0
dim : [ 3 193 229 193 1 1 1 1]
intent_p1 : 0.0
intent_p2 : 0.0
intent_p3 : 0.0
intent_code : none
datatype : float32
bitpix : 32
slice_start : 0
pixdim : [1. 1. 1. 1. 0. 0. 0. 0.]
vox_offset : 0.0
scl_slope : nan
scl_inter : nan
slice_end : 0
slice_code : unknown
xyzt_units : 2
cal_max : 0.0
cal_min : 0.0
slice_duration : 0.0
toffset : 0.0
glmax : 0
glmin : 0
descrip : b'xform matrices modified by FixHeaderApplyTransforms (niworkflows v1.1.12).'
aux_file : b''
qform_code : mni
sform_code : mni
quatern_b : 0.0
quatern_c : 0.0
quatern_d : 0.0
qoffset_x : -96.0
qoffset_y : -132.0
qoffset_z : -78.0
srow_x : [ 1. 0. 0. -96.]
srow_y : [ 0. 1. 0. -132.]
srow_z : [ 0. 0. 1. -78.]
intent_name : b''
magic : b'n+1'
Some of the important information in the header is information about the orientation of the image in space. This can be represented as the affine matrix, which can be used to transform images between different spaces.
data.affine
array([[ 1., 0., 0., -96.],
[ 0., 1., 0., -132.],
[ 0., 0., 1., -78.],
[ 0., 0., 0., 1.]])
We will dive deeper into affine transformations in the preprocessing tutorial.
Plotting Data with Nilearn¶
There are many useful tools from the nilearn library to help manipulate and visualize neuroimaging data. See their documentation for an example.
In this section, we will explore a few of their different plotting functions, which can work directly with nibabel instances.
%matplotlib inline
from nilearn.plotting import view_img, plot_glass_brain, plot_anat, plot_epi
plot_anat(data)
<nilearn.plotting.displays.OrthoSlicer at 0x7fadd13c4c50>
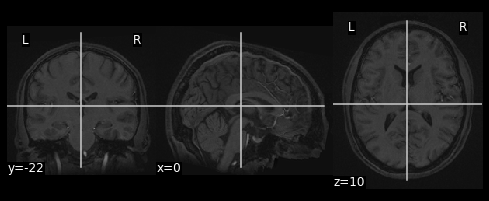
Nilearn plotting functions are very flexible and allow us to easily customize our plots
plot_anat(data, draw_cross=False, display_mode='z')
<nilearn.plotting.displays.ZSlicer at 0x7fadc157fd50>

try to get more information how to use the function with ? and try to add different commands to change the plot.
nilearn also has a neat interactive viewer called view_img for examining images directly in the notebook.
view_img(data)
The view_img function is particularly useful for overlaying statistical maps over an anatomical image so that we can interactively examine where the results are located.
As an example, let’s load a mask of the amygdala and try to find where it is located.
amygdala_mask = nib.load(os.path.join('..', 'masks', 'FSL_BAmyg_thr0.nii.gz'))
view_img(amygdala_mask, data)
/Users/lukechang/anaconda3/lib/python3.7/site-packages/nilearn/image/resampling.py:513: UserWarning: Casting data from int32 to float32
warnings.warn("Casting data from %s to %s" % (data.dtype.name, aux))
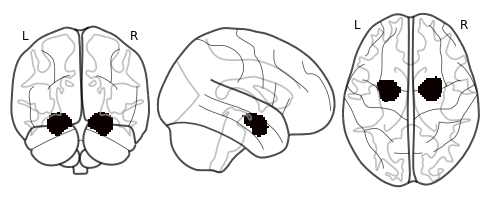
We can also plot a glass brain which allows us to see through the brain from different slice orientations. In this example, we will plot the binary amygdala mask.
plot_glass_brain(amygdala_mask)
<nilearn.plotting.displays.OrthoProjector at 0x7fad3841fd90>
Manipulating Data with Nltools¶
Ok, we’ve now learned how to use nibabel to load imaging data and nilearn to plot it.
Next we are going to learn how to use the nltools package that tries to make loading, plotting, and manipulating data easier. It uses many functions from nibabe, nilearn, and other python libraries. The bulk of the nltools toolbox is built around the Brain_Data() class. The concept behind the class is to have a similar feel to a pandas dataframe, which means that it should feel intuitive to manipulate the data.
The Brain_Data() class has several attributes that may be helpful to know about. First, it stores imaging data in .data as a vectorized features by observations matrix. Each image is an observation and each voxel is a feature. Space is flattened using nifti_masker from nilearn. This object is also stored as an attribute in .nifti_masker to allow transformations from 2D to 3D/4D matrices. In addition, a brain_mask is stored in .mask. Finally, there are attributes to store either class labels for prediction/classification analyses in .Y and design matrices in .X. These are both expected to be pandas DataFrames.
We will give a quick overview of basic Brain_Data operations, but we encourage you to see our documentation for more details.
Brain_Data basics¶
To get a feel for Brain_Data, let’s load an example anatomical overlay image that comes packaged with the toolbox.
from nltools.data import Brain_Data
from nltools.utils import get_anatomical
anat = Brain_Data(get_anatomical())
anat
nltools.data.brain_data.Brain_Data(data=(238955,), Y=0, X=(0, 0), mask=MNI152_T1_2mm_brain_mask.nii.gz, output_file=[])
To view the attributes of Brain_Data use the vars() function.
print(vars(anat))
{'mask': <nibabel.nifti1.Nifti1Image object at 0x7fad95829a50>, 'nifti_masker': NiftiMasker(detrend=False, dtype=None, high_pass=None, low_pass=None,
mask_args=None,
mask_img=<nibabel.nifti1.Nifti1Image object at 0x7fad95829a50>,
mask_strategy='background', memory=Memory(cachedir=None),
memory_level=1, reports=True, sample_mask=None, sessions=None,
smoothing_fwhm=None, standardize=False, t_r=None,
target_affine=None, target_shape=None, verbose=0), 'data': array([1875., 2127., 2182., ..., 5170., 5180., 2836.], dtype=float32), 'Y': Empty DataFrame
Columns: []
Index: [], 'X': Empty DataFrame
Columns: []
Index: [], 'file_name': []}
Brain_Data has many methods to help manipulate, plot, and analyze imaging data. We can use the dir() function to get a quick list of all of the available methods that can be used on this class.
To learn more about how to use these tools either use the ? function, or look up the function in the api documentation.
print(dir(anat))
['X', 'Y', '__add__', '__class__', '__delattr__', '__dict__', '__dir__', '__doc__', '__eq__', '__format__', '__ge__', '__getattribute__', '__getitem__', '__gt__', '__hash__', '__init__', '__init_subclass__', '__iter__', '__le__', '__len__', '__lt__', '__module__', '__mul__', '__ne__', '__new__', '__radd__', '__reduce__', '__reduce_ex__', '__repr__', '__rmul__', '__rsub__', '__setattr__', '__setitem__', '__sizeof__', '__str__', '__sub__', '__subclasshook__', '__weakref__', 'aggregate', 'align', 'append', 'apply_mask', 'astype', 'bootstrap', 'copy', 'data', 'decompose', 'detrend', 'distance', 'dtype', 'empty', 'extract_roi', 'file_name', 'filter', 'find_spikes', 'groupby', 'icc', 'iplot', 'isempty', 'mask', 'mean', 'median', 'multivariate_similarity', 'nifti_masker', 'plot', 'predict', 'predict_multi', 'r_to_z', 'randomise', 'regions', 'regress', 'scale', 'shape', 'similarity', 'smooth', 'standardize', 'std', 'sum', 'threshold', 'to_nifti', 'transform_pairwise', 'ttest', 'upload_neurovault', 'write']
Ok, now let’s load a single subject’s functional data from the localizer dataset. We will load one that has already been preprocessed with fmriprep and is stored in the derivatives folder.
Loading data can be a little bit slow especially if the data need to be resampled to the template, which is set at \(2mm^3\) by default. However, once it’s loaded into the workspace it should be relatively fast to work with it.
data = Brain_Data(layout.get(target='subject', scope='derivatives', suffix='bold', extension='nii.gz', return_type='file')[0])
Here are a few quick basic data operations.
Find number of images in Brain_Data() instance
print(len(data))
128
Find the dimensions of the data (images x voxels)
print(data.shape())
(128, 238955)
We can use any type of indexing to slice the data such as integers, lists of integers, slices, or boolean vectors.
import numpy as np
print(data[5].shape())
print(data[[1,6,2]].shape())
print(data[0:10].shape())
index = np.zeros(len(data), dtype=bool)
index[[1,5,9, 16, 20, 22]] = True
print(data[index].shape())
(238955,)
(3, 238955)
(10, 238955)
(6, 238955)
Simple Arithmetic Operations¶
Calculate the mean for every voxel over images
data.mean()
nltools.data.brain_data.Brain_Data(data=(238955,), Y=0, X=(0, 0), mask=MNI152_T1_2mm_brain_mask.nii.gz, output_file=[])
Calculate the standard deviation for every voxel over images
data.std()
nltools.data.brain_data.Brain_Data(data=(238955,), Y=0, X=(0, 0), mask=MNI152_T1_2mm_brain_mask.nii.gz, output_file=[])
Methods can be chained. Here we get the shape of the mean.
print(data.mean().shape())
(238955,)
Brain_Data instances can be added and subtracted
new = data[1]+data[2]
Brain_Data instances can be manipulated with basic arithmetic operations.
Here we add 10 to every voxel and scale by 2
data2 = (data + 10) * 2
Brain_Data instances can be copied
new = data.copy()
Brain_Data instances can be easily converted to nibabel instances, which store the data in a 3D/4D matrix. This is useful for interfacing with other python toolboxes such as nilearn
data.to_nifti()
<nibabel.nifti1.Nifti1Image at 0x7fad966b7d10>
Brain_Data instances can be concatenated using the append method
new = new.append(data[4])
Lists of Brain_Data instances can also be concatenated by recasting as a Brain_Data object.
print(type([x for x in data[:4]]))
type(Brain_Data([x for x in data[:4]]))
<class 'list'>
nltools.data.brain_data.Brain_Data
Any Brain_Data object can be written out to a nifti file.
data.write('Tmp_Data.nii.gz')
Images within a Brain_Data() instance are iterable. Here we use a list comprehension to calculate the overall mean across all voxels within an image.
[x.mean() for x in data]
[3631.2645411383587,
3637.836965559738,
3634.8721272399216,
3629.901022394308,
3625.903680905571,
3629.8617967834693,
3647.0626827990523,
3656.532783431514,
3652.9664477289007,
3656.854690370624,
3651.158568986219,
3646.0627760781335,
3647.096514090842,
3650.3529496858014,
3647.3099736730073,
3647.541164716155,
3653.0196194154546,
3653.9954711802293,
3648.761361342424,
3643.4910051915754,
3644.4916183059545,
3643.806287863885,
3632.513377052877,
3634.0742188451927,
3632.823087421774,
3636.538413516169,
3635.2725020511252,
3641.7997040537466,
3641.7916592727656,
3634.091262543454,
3643.245243803917,
3658.5574913389905,
3649.2724227942545,
3641.1560643044045,
3643.306476451434,
3637.0167340942126,
3637.5381102659767,
3644.4683410479392,
3639.8860350581976,
3630.9967110874504,
3623.7886672981303,
3627.072535710563,
3624.862147866512,
3622.6118047366986,
3634.9950195308434,
3627.3577482514256,
3628.0705544219018,
3621.129485290891,
3616.061808421585,
3608.6081438384495,
3619.78010303786,
3625.2043623406903,
3630.7597935028207,
3628.074661527296,
3630.138505445051,
3624.1916798686207,
3620.2774727712167,
3619.0700248246812,
3624.4436554897025,
3625.009898536367,
3622.018871417351,
3629.2243599621006,
3629.480077460646,
3625.544210353266,
3621.4695822776903,
3617.3724419581886,
3615.911084856664,
3614.292718966583,
3616.767158878271,
3621.5679265347426,
3617.094424744487,
3609.954978219352,
3612.64425239096,
3629.0631390560125,
3628.8013229265916,
3621.5916670872352,
3612.4806693745804,
3613.664459683712,
3621.6783653848643,
3621.143953281178,
3618.5757894664835,
3610.795271247279,
3613.4845495891113,
3607.408626131088,
3613.440184819298,
3608.650315768319,
3604.885826645298,
3601.629542348782,
3600.8264436489476,
3600.6285381425578,
3609.776906766102,
3618.2023236145965,
3615.7040390888783,
3612.2955410039767,
3606.200637253472,
3623.39621843859,
3627.132987563558,
3611.296930448837,
3594.7923511331287,
3580.0196095574156,
3579.4805425330965,
3583.0559348949373,
3592.5569828498697,
3604.371337719925,
3606.9999113264666,
3620.9576329138504,
3617.235063465483,
3612.5929641090283,
3605.798535577046,
3597.116219752562,
3588.5229574072764,
3587.5091257654085,
3598.2696343420794,
3602.2806983812598,
3601.700440752411,
3610.3855186675264,
3610.527882720576,
3604.287286181301,
3591.7958436327026,
3591.129841385018,
3598.8536387360964,
3611.565702027962,
3610.1719483427555,
3618.0720138472166,
3612.4640399870646,
3598.581193499466,
3594.3173923249437,
3595.754862354543]
Though, we could also do this with the mean method by setting axis=1.
data.mean(axis=1)
array([3631.26454114, 3637.83696556, 3634.87212724, 3629.90102239,
3625.90368091, 3629.86179678, 3647.0626828 , 3656.53278343,
3652.96644773, 3656.85469037, 3651.15856899, 3646.06277608,
3647.09651409, 3650.35294969, 3647.30997367, 3647.54116472,
3653.01961942, 3653.99547118, 3648.76136134, 3643.49100519,
3644.49161831, 3643.80628786, 3632.51337705, 3634.07421885,
3632.82308742, 3636.53841352, 3635.27250205, 3641.79970405,
3641.79165927, 3634.09126254, 3643.2452438 , 3658.55749134,
3649.27242279, 3641.1560643 , 3643.30647645, 3637.01673409,
3637.53811027, 3644.46834105, 3639.88603506, 3630.99671109,
3623.7886673 , 3627.07253571, 3624.86214787, 3622.61180474,
3634.99501953, 3627.35774825, 3628.07055442, 3621.12948529,
3616.06180842, 3608.60814384, 3619.78010304, 3625.20436234,
3630.7597935 , 3628.07466153, 3630.13850545, 3624.19167987,
3620.27747277, 3619.07002482, 3624.44365549, 3625.00989854,
3622.01887142, 3629.22435996, 3629.48007746, 3625.54421035,
3621.46958228, 3617.37244196, 3615.91108486, 3614.29271897,
3616.76715888, 3621.56792653, 3617.09442474, 3609.95497822,
3612.64425239, 3629.06313906, 3628.80132293, 3621.59166709,
3612.48066937, 3613.66445968, 3621.67836538, 3621.14395328,
3618.57578947, 3610.79527125, 3613.48454959, 3607.40862613,
3613.44018482, 3608.65031577, 3604.88582665, 3601.62954235,
3600.82644365, 3600.62853814, 3609.77690677, 3618.20232361,
3615.70403909, 3612.295541 , 3606.20063725, 3623.39621844,
3627.13298756, 3611.29693045, 3594.79235113, 3580.01960956,
3579.48054253, 3583.05593489, 3592.55698285, 3604.37133772,
3606.99991133, 3620.95763291, 3617.23506347, 3612.59296411,
3605.79853558, 3597.11621975, 3588.52295741, 3587.50912577,
3598.26963434, 3602.28069838, 3601.70044075, 3610.38551867,
3610.52788272, 3604.28728618, 3591.79584363, 3591.12984139,
3598.85363874, 3611.56570203, 3610.17194834, 3618.07201385,
3612.46403999, 3598.5811935 , 3594.31739232, 3595.75486235])
Let’s plot the mean to see how the global signal changes over time.
plt.plot(data.mean(axis=1))
[<matplotlib.lines.Line2D at 0x7fad966a6590>]
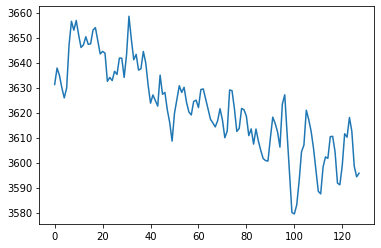
Notice the slow linear drift over time, where the global signal intensity gradually decreases. We will learn how to remove this with a high pass filter in future tutorials.
Plotting¶
There are multiple ways to plot your data.
For a very quick plot, you can return a montage of axial slices with the .plot() method. As an example, we will plot the mean of each voxel over time.
f = data.mean().plot()
threshold is ignored for simple axial plots

There is an interactive .iplot() method based on nilearn view_img.
data.mean().iplot()
Brain_Data() instances can be converted to a nibabel instance and plotted using any nilearn plot method such as glass brain.
plot_glass_brain(data.mean().to_nifti())
<nilearn.plotting.displays.OrthoProjector at 0x7fad07c45a10>
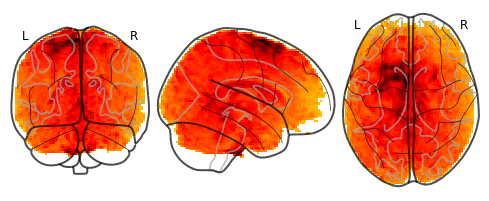
Ok, that’s the basics. Brain_Data can do much more!
Check out some of our tutorials for more detailed examples.
We’ll be using this tool throughout the course.
For homework, let’s practice our skills in working with data.
Exercises¶
Exercise 1¶
A few subjects have already been preprocessed with fMRI prep.
Use pybids to figure out which subjects have been preprocessed.
Exercise 2¶
One question we are often interested in is where in the brain do we have an adequate signal to noise ratio (SNR). There are many different metrics, here we will use temporal SNR, which the voxel mean over time divided by it’s standard deviation. $\(\text{tSNR} = \frac{\text{mean(voxel_{i})}}{\text{std(voxel_{i})}}\)$
In Exercise 2, calculate the SNR for S01 and plot this so we can figure which regions have high and low SNR.
Exercise 3¶
We are often interested in identifying outliers in our data. In this exercise, find any image from ‘S01’ that exceeds a zscore of 2 and plot each one.